 For me, the star attraction of March Mathness is matrix rotation. It’s a new toy (um, tool) for me that’s exciting on two levels: Firstly, it answers key questions I’ve had about rotation, especially with regard to 4D (let alone 3D or easy peasy 2D). Secondly, I’ve never had a handle on matrix math, and thanks to an extraordinary YouTube channel, now I see it in a whole new light.
For me, the star attraction of March Mathness is matrix rotation. It’s a new toy (um, tool) for me that’s exciting on two levels: Firstly, it answers key questions I’ve had about rotation, especially with regard to 4D (let alone 3D or easy peasy 2D). Secondly, I’ve never had a handle on matrix math, and thanks to an extraordinary YouTube channel, now I see it in a whole new light.
Literally (and I do mean “literally” literally), I will never look at a matrix the same way again. Knowing how to look at them changes everything. That they turned out to be exactly what I needed to understand rotation makes the whole thing kinda wondrous.
I’m going to try to provide an overview of what I learned and then point to a great set of YouTube videos if you want to learn, too.
There is no question we invent the language of math. (The question is what — if anything real — does that language describe?)
When it comes to rotation, for which many real physical cases exist, there are related mathematical “dialects” that all accomplish the same thing: rotating a point.
This rotation is a linear process (we can rotate a little or a lot). We can view it as a function that takes some coordinates (a point) and produces new coordinates that are rotated some number of degrees around an axis.
We can formalize this function as:

Where P0 is the point to rotate, and P1 is the result, rotated θ (theta) degrees about the axis described by F (phi), which is a vector pointing from the origin.
§
At least three mathematical dialects let us build the rotate() function.
They’re all related and generally amount to the same amount of actual work. I’ll call them: Trigonometry, Complex, and Matrix.
The point of this post is the last one, so I’ll cover the other two fairly briefly.
Here in the 2D world of screens, it’s easiest to start with 2D rotation. Our axis of rotation is the z axis.
Everything there applies to higher dimensions (there’s just more of it).
Trigonometry
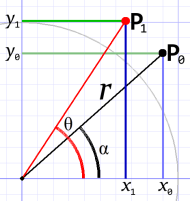
Diagram 1. Trig-style.
The “old-fashioned” almost “brute force” way involves trigonometry. (So does a rotation matrix, but in a much simpler way.)
Essentially, we use a common (but special) trig function, called atan2, to figure out the point’s current angle, a (alpha), relative to the x axis.
We use Pythagoras to calculate the point’s distance (r) from the axis.
The current angle, a, plus the rotation angle, θ, along with the distance (r), allows us to calculate the new x and y.
Here’s the math:

It works just fine, although it requires doing all the calculations for each point to rotate. It works well in cases where you rotate one point of known distance repeatedly, generating a circular motion. Often, only the last two bits of math are needed.
(Note: The atan2 trig function is a little funky; not all math libraries offer it. Using the more standard atan function complicates the math slightly.)
Complex Numbers
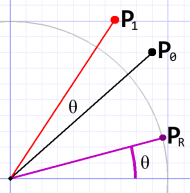
Diagram 2. Complex style.
As I mentioned in the Quaternions post, complex numbers are inherently two-dimensional, so they can be interpreted as points on the complex plane.
When we do that, an interesting property emerges: multiplying one complex number by another produces a new number that is rotated with respect to the origin.
Rotation angle, as always, is referenced from the x axis (counterclockwise).
If point A has an angle of 30°, and point B has an angle of 10°, then A×B results in a point with an angle of 40°.
The caveat is that at least one point needs to have a distance (from the origin) of one, otherwise the distance of the new point will be the product of A and B. It means the point we use to rotate needs a distance of one (it needs to be a unit vector).
Here’s the math:
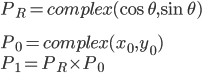
Two nice things here: We can deal in more holistic points (as complex numbers) rather than x,y pairs.
Also, because it depends only on the angle, the rotation point, PR, can be calculated early and used for all points. No need to recalculate it.
The complex numbers are great for 2D, but we need quaternions to do the same thing in 3D. (I don’t know if octonions enable 4D rotation the way quaternions do for 3D. I’m not entirely sure “rotation” makes sense in 4D.)
Still, I’d bet there is an N-dimensional generalization that uses complex numbers. I’d also bet it gets pretty complicated.
Matrix rotation generalizes much more nicely.
The Matrix!

Diagram 3a. Matrix style.
The downside is that matrices can look a little horrific at first, and they are often taught in a way that’s equally horrific.
Most of us were introduced to matrices in high school or college math, taught the rote ways of doing math on them, subjected to some exercises using that math, and that may have been all.
If things went deeper, it probably involved how a matrix can alter a vector. My college linear algebra book gets seriously into proofs about those transformations, but never really opens the door to what is really going on.
Which is pretty cool, very geometrical, and not that challenging to grasp. (Granted we’re only looking at a small part of matrix mathematics. Shallow water that won’t drown us!)
§
Let’s start with what a matrix looks like (and, more importantly, what it means). Here is a simple 2×2 matrix:
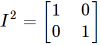
This says we’re associating the name, I2, to a 2×2 matrix with the four values shown (in the row-column order shown).
Note the name doesn’t mean “I-squared.” The little “2” is part of the name. It tells us that I2 is a two-dimensional object. I named it “I” because the values shown make this a 2D identity matrix.
In other words, if we multiply some other matrix by I2, the result is a copy of the other matrix. This is like multiplying a number by 1; the result is a copy of the number. (I mentioned identity elements recently in a Noether post.)
To open the door on what a matrix means, let me show you another 2×2 matrix (which I’ll call T2, a 2D transform):
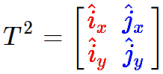
When we look at a 2×2 matrix, what we should see is two vertical columns, both of which are 2D vectors (with an x and y). We’ll call the one on the left (in red) “i-hat” and the one on the right (in blue) “j-hat” (the “hat” for the circumflex they both wear).
The “hat” means an object is a unit vector, an “arrow” with a length of one.
So, a 2×2 matrix has two vectors, i-hat and j-hat, which we think of as initially associated with the x and y axes (respectively). Consider the identity matrix, I2, in this new light:

We imagine i-hat is initially set to (x=1, y=0), so it is a unit vector that lies along the x axis. It is, in fact, the x basis vector for the 2D space. As such, we could also call it x-hat.
Likewise, we imagine j-hat is initially set to (x=0, y=1), so it is also a unit vector, but it lies along the y axis. It is the y basis vector for the space. We could call it y-hat.
Note that we call them ‘i‘ and ‘j‘ (rather than ‘x’ and ‘y’) because a transform can move them off the x or y axis.
Essentially, we start by imagining a transformation matrix initially is the identity matrix!
§
I say we “imagine” the initial setting because we look at the actual values of the matrix as representing a transformation.
The values of the matrix tell us where i-hat and j-hat end up because the transformation.
This is why the identity matrix doesn’t change anything. The imagined initial values and the actual values are the same, so i-hat and j-hat don’t change.
Crucially here, any 2D point can be thought of in terms of the basis vectors, x-hat and y-hat:
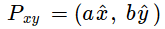
That is, any point is some number, a, times x-hat and some other number, b, times y-hat. (This is what we really mean any time we work with x and y. We just don’t usually break it down in terms of basic vectors.)
The magic of transformation is that, when we transform i-hat and j-hat, any transformed point has the same relationship to them as it did to x-hat and y-hat before the transform.
By knowing where i-hat and j-hat end up, we know where any point we want to transform goes.
§
Now let’s consider how we can rotate with a matrix transformation:

Diagram 3b. A 2×2 matrix describes where i-hat and j-hat end up assuming they started as x-hat and y-hat, respectively.
The diagram above illustrates several parts of the process:
Firstly, x-hat (dark blue horizontal) and y-hat (dark green vertical) are the original basis vectors for the (original) 2D space. The lines are a visual representation of the I2 identity matrix.
Secondly, i-hat (slanted light blue) and j-hat (slanted light green) are the basis vectors for the transformed space. They are a visual representation of a rotation matrix (described below).
Thirdly, the original point, P0 (black), and transformed point, P1 (red), which is rotated by θ (theta) degrees.
As mentioned above, P0, has an x and y that relate to x-hat and y-hat through constants (a and b, which on the diagram are 0.9 and 0.8, respectively):

This is important, because the rotated point, P1, has the same relationship with i-hat and j-hat:

As you can see in the diagram above.
This is the foundation of all linear matrix transforms!
The matrix values tell us where i-hat and j-hat go. To transform a point, we just consider its relationship to x-hat and y-hat (its x and y values) and then apply those values to i-hat and j-hat.
(Another way to view it is that a matrix describes new basis vectors that transform a space.)
§
At this point there are, perhaps, at least two obvious questions:
- How do we make a rotation matrix?
- How do we use a rotation matrix?
There is also the question of how all this applies to four-dimensional tesseractae (which it so does).
In the next installment I’ll try to answer the first two questions as well as (at least) setting the stage for extending this to three and four dimensions. (As you might guess, we just add more rows and columns.)
As a foretaste, here’s the rotation matrix for the diagram above:

See how the two columns have the x (top) and y (bottom) values for the i-hat and j-hat vectors on the diagram?
§
Stay tuned, my friends!














March 29th, 2019 at 10:06 am
“The question is what — if anything real — does that language describe?”
I come down on the side that, at least at the foundations, it is based on something real. Mathematics are our most foundational theories about reality. Of course, like all theories, not all of the derived ones reflect reality, although just as speculative scientific theories so sometimes turn out to reflect reality, so do mathematical constructs.
For me, this explains the “unreasonable effectiveness” of mathematics. Though I know a lot of mathematicians strongly feel different.
March 29th, 2019 at 11:59 am
It might boil down to this question: Is a perfect circle something we invent (by abstracting imperfect physical circles) or something we discover (by realizing what imperfect physical circles represent)?
A re-phrasing might ask: How real is π? If a perfect circle is real, so is π. If perfect circles are just abstractions of reality, so is π.
I lean towards perfect circles and π as a discovery, but I admit I’m confounded by the same problem ever since Plato. Just exactly where do these things exist, then? But if they are just abstractions, then the amazing beauty and elegance seem to be saying something about physical reality.
(Have you read Neal Stephenson’s Anathem? In that one there are multiple realities of higher and lower mathematical perfection, a mesh network, with a flow from perfect to not perfect. I really enjoyed the first 9/10 of it. I tend to like Stephenson’s work a lot… kinda up my alley. 🙂 )
March 29th, 2019 at 2:44 pm
I tend to think that a circle is a concept we invent, although it might be more accurate to say evolution invented them since our perceptual systems seem wired to perceive them. In that sense, they’re an almost inevitable invention, one that an alien in Andromeda seems almost certain to have too.
I can see the argument that this convergence represents some Platonic form, although I’m not sure what we do with that information if we come to that conclusion.
I haven’t read Anathem. It sounds interesting, but I’ve struggled with other Stephenson books in the past. He has a tendency to go down narrative rabbit holes, which is great if it’s something you’re interested in, but tedious if you’re not. (I recall Tom Clancy being similar, although his rabbit holes tended to be technological.)
March 29th, 2019 at 3:54 pm
“In that sense, [circles are] an almost inevitable invention,”
Sooooo inevitable! “All points equal distance from a given point.” It seems to transcend our perceptual system. Lots of natural objects certainly point at the idea.
“I can see the argument that this convergence represents some Platonic form,…”
Exactly. 🙂 And exactly. 😦
“I haven’t read Anathem.”
Stephenson really is a matter of taste. I usually really take to him. (I used to like Clancy a lot, too, but he wore me out once he started to serialize.)
Part of it for me, I think, is how rare someone like Stephenson is for someone like me. You can tell from my blog I have a wide range of interests, but most of them centered around hard science. But also connected with art and literature, especially storytelling.
That diamond-hard SF is a delight to me. I see it less as (often questionable) literature and more as technical manuals and science books brought to life. So I excuse writing flaws far more willingly than I might stories that take themselves more seriously.
It’s kind of a niche, but I’ve been a fan going way back.
March 29th, 2019 at 5:24 pm
I enjoy hard science fiction too, although not when it starts to feel like a science textbook, at least unless I’m currently into that science topic. In fiction, the science works best for me when it’s integrated into the story. I can tolerate short sidebars, but when it turns into a long rabbit hole (like Clarke’s whole chapter of the star child diving into Jupiter), it gets tedious and turns into a chore to read.
I think this is one reason why I usually enjoy Greg Egan’s short stories more than his novels. The novels give him too much space to indulge his mathematical and physics predilections.
March 29th, 2019 at 9:50 pm
I have not met many SF fans with quite my tolerance for that sort of thing. (We few are probably why it gets written at all. 🙂 )
On the flip side, also in contrast with most readers, I find lots of description boring. I generally don’t care about the clothing or weather or furnishings — unless they have a bearing on the plot.
There’s a bit in TOS where (IIRC) Kirk says Scotty keeps turning down shore leave because he’d rather hang out in his quarters reading tech manuals, that’s what he considers fun. (I think it’s the one where Kirk forces Scotty to go, and Scotty gets “possessed” by the Jack-the-Ripper alien.)
I realized long ago: I’m Scotty. (And, indeed, I would rather head Engineering than the whole ship.) Hard SF is tech manuals with lots of flavor. Imaginative tech manuals.
Although I never really got into the actual SF tech manuals, not deeply, anyway. I do (did?) have some “tech manuals” for the Enterprise, but there’s a whole world of that sort of thing out there. Especially Star Wars ships. Fans have really gotten into that. I thought I heard one of those car manual companies (Chilton, maybe?) was getting into SF manuals.
[shrug] I guess I like the extra flavor of the hard SF than an actual manual, but I’m definitely more prone to that sort of thing than most.
March 30th, 2019 at 8:32 am
Actually I’m not a fan of lots of description either. I just need enough to give me an idea of the setting (if it’s relevant). I’m also not a fan of too much character introspection, particularly in the middle of action sequences. Both feel like they bog the story down.
It’s currently considered bad to have infodumps. I actually don’t mind them, in moderation. I prefer a relevant infodump to pointless descriptions of people’s clothing or landscape.
Strangely enough, as a boy, I really got into those SF reference manuals. But I never read them straight through, but focused on whatever bits and pieces I found interesting. At least until I realized that most of that stuff wasn’t canonical for whatever franchise it applied to.
Somewhere I have a book detailing the history of all federation spaceships until the Enterprise. It was utterly blown away later by the TV shows that came after it was published, but it was someone’s interesting take on it. I also have astrogation maps and a manual reconciling how warp drive worked with interstellar realities (something to do with the density of matter in the local region of space). Again, someone’s interesting take that didn’t hold up to later shows.
I also really enjoyed the appendices at the back of the Lord of the Rings and Dune. Again, I didn’t read them straight through.
I think my issue with having too much of this stuff in the actual story is, there, it isn’t optional. Even if it’s utterly irrelevant to the story, you as the reader can’t assume that. It might be relevant later. So you have to read it.
March 30th, 2019 at 10:30 am
So true. The author put it there, it must be important, right?
That’s a good point about technical material, not reading it straight through but selectively. Likewise. It was fun to page through and get a sense of, but I think I outgrew the interest. (Sounds like you might have, too.)
When I was in high school, a couple guys I knew and I used to design these fantasy fortresses — kind of like Batcaves or Superman’s Fortress of Solitude. The sort of thing you used to see in the comics when they’d show you a big spread, labeled!, of the Batcave or whatever. But as I began to design and build real things, that interest died.
And, as you point out, most of it was never canonical, so it was doubly not real.
I’m quite certain I’ve only, at best, ever skimmed the appendices of LotR or Dune! Maybe read a few bits that stuck out. I think Tolkien really appeals to those with more of a regard for history and languages than I seem to have. His world-building was amazing, though!
“I’m also not a fan of too much character introspection, particularly in the middle of action sequences.”
That’s an aspect of Donaldson that bugs me. Middle of an action sequence, and the hero is deep in their own mind struggling with some conflict. [sigh] [slap] Wake up! The battle’s over here, fool!
Honestly, I’ve gotten as tired of battle sequences in books as I have in movies (I really can’t stand them in movies anymore; they’re just too absurd). The smaller action pieces are okay, but the big battles? They never seem right to me. Much too staged.
One thing I’ve realized, my love of super hard SF aside, is that I most like books with lots of quotes. I like lots of dialog, people talking. Description, internal rumination, is fine, but let’s get back to the dialog! 🙂
March 30th, 2019 at 11:49 am
I do like history, so whenever I see an appendix, that’s usually what I look for first, a chronology or some type of historical narrative. Although I’ve read other appendices explaining how a spacecraft worked, or how a society was organized. In LOTR, the thing I focused on was the chronology, which showed how far back the history of Middle Earth actually went. (Frustratingly at the time, it didn’t cover the Elder Days. You had to read The Silmarillion to get that, although now it’s all over the internet.)
On quotes, I read a tip from an author years ago. When you’re considering a book in the store, and want an idea how fast paced it is, turn to random locations in the book. If most of them have quotes, it’ll at least feel like a fast moving story. If most of them don’t, it will be slower. I’ve generally found this to be true, and to be leery of books where the quote ratio is low.
But it seems like the overall quote ratio has gone down for most books written since the rise of word processing software.
March 30th, 2019 at 3:24 pm
That author’s tip makes good sense. (I’ll be sure to use it if I’m ever actually in a book store again! 😀 )
With some authors, when they get lost in character or scene contemplation, sometimes I just start skimming, spot reading sentences, until I hit quotes. Kinda depends on what’s going on in the scene, I suppose.
Is your observation based on data you’ve seen or first impressions? Why do you think it’s happened? Just because the technology, or does it represent a cultural shift?
Long ago, a friend of mine who worked in advertising, read some of my college writing, and one thing she said was that modern writing is much punchier. Compound clauses are rare. Very much not how I wrote (or still write), but I did try to keep it in mind.
Seems like all sorts of ways we compress data and time in these fast-paced times. (And it makes reading old fiction kind of weird, sometimes.)
March 30th, 2019 at 4:09 pm
On the author’s tip and being in a book store, yeah. I think I’ve been in a bookstore once in the last year, and it was just to use the bathroom. But quote checking also works on Amazon previews.
It’s very much my subjective observation, and may only pertain to the type of fiction I read, science fiction and fantasy. I know I didn’t get that feel when reading, for instance, The Da Vinci Code. (That book frequently is savaged for its writing quality, but it was a bestseller, in part I think, because it’s easy to read.)
My theory is that the change happened because word processing software made it easier to go back and beef up descriptions and narration. When people had to re-type each draft on a typewriter, it seemed a lot less common.
That, and editors seem to encourage it. One writer interviewed on the Writing Excuses podcast, who had previously only published short fiction, noted that he had been told by his editor he needed to spread out more, to stop writing like he had a word limit. I wish I could talk with that editor and tell them, as a reader, I wish everyone wrote like they had a word limit.
March 31st, 2019 at 10:09 am
Be kind of neat if ebooks started publishing their quote ratio. (Certainly would be an easy thing to calculate… wonder if I can access the text of my ebooks to try it. Hmm…)
Your theory makes sense, and what you said about editors, as well. I think part of it is economics. A fatter book commands a higher price; people won’t pay big bucks for a skinny book.
I’ve watched the size of books grow, not just in general, but even in long-running series by a single author about the same character telling the same sorts of stories. And yet, in the modern era, it apparently takes two or three times as much telling to tell the same sort of story.
Gratuitous description, gratuitous scenes, gratuitous flashbacks and background,… It’s interesting sometimes to go re-read the older, skinnier, books and realize how well they moved, how well they told their story, how much just isn’t missing from those shorter stories..
(Heh, I even ranted about this way back in 2014. From the title of that post, I thought it was the one I talked about American Gods, a book I loved and enjoyed the first season of the TV version. But that was the Frogs of Fantasy post. 🙂 I’m also really looking forward to Good Omens on Prime. I love both those books!)
I’m with you: Writers should act like they have a word limit. Tight writing is best by a long shot.
I wonder if the rise of ebooks will change the gratuitous length thing. With books no longer tied to physical production costs, perhaps pricing will be more proportional and some of the push to write long will go away.
March 31st, 2019 at 1:28 pm
A published quote ratio would be a nice thing. Although if it ever became an actual thing, people would find some way to game it. Amazon has to change some of its algorithms periodically in a constant whack a mole with people gaming the ratings and payment systems.
It looks like ebooks are already making a difference. There’s been a resurgence in novellas in the last few years. Given that they can be pushed out faster, and almost certainly have a higher revenue / effort ratio, we might see a lot more of them, particularly for series. Of course, the independents are selling novels for the price the traditionals are charging for novellas, so not sure what will happen.
March 31st, 2019 at 3:13 pm
“Although if it ever became an actual thing, people would find some way to game it.”
[sigh] So true. 😦
This is exactly why humanity can’t have nice things.
“It looks like ebooks are already making a difference.”
As did digital music. As did video. It’s funny how many people insist “It was ever thus!”
Quite to the contrary, the world has really changed. People themselves haven’t, but the world, its tech, the sheer scope of things, not like anything in our past. I don’t know why more people aren’t terrified about our likely future. The last few years are such a clear bellwether.
March 31st, 2019 at 4:55 pm
You mentioned that you don’t really like history much. I don’t read it nearly as much as I used to, but one benefit, when you read about how clueless people in the past were, how blighted and parochial their understanding of what was going on, including the leadership, it makes you feel better about people today and our future prospects, at least it does for me.
Sean Carroll in his Mindscape podcast recently interviewed Edward Watts on the fall of the Roman Republic. Even though I already had some familiarity with the subject, it was interesting to hear a discussion of how the republic degraded over time, eventually falling into empire. I think being familiar with what a society that actually was in trouble looked like (late Roman Republic, late Roman Empire, US just before the civil war, etc) is useful for assessing where our own civilization is at the moment.
April 1st, 2019 at 10:25 am
“…how clueless people in the past were, how blighted and parochial their understanding of what was going on, including the leadership,…”
That’s the “it was ever thus argument,” and I think it’s increasingly wishful thinking these days. People haven’t changed, but society and culture have. In important and scary ways.
I’m not ignorant of history, and good fiction (I think) offers a better view into ordinary life in ages past. History tends to be about power and nations and inventions, but fiction offers insight into how people thought and behaved. (It’s part of the fascination for me in A.C. Doyle, for one example: all the background info about life in those times.)
I dunno. Maybe I am being Chicken Little or Cassandra, but I knew Trump would win and why. I also understand why his support continues, why England is crazy under Brexit, and why nationalism is on the rise globally. Things I’ve been warning about for 40 years are coming true.
History also teaches us that civilizations do collapse, that empires don’t last, and the best laid plans go astray. As the poet said, “The center cannot hold.”
“I think being familiar with what a society that actually was in trouble looked like…”
To some extent, no doubt. But what society ever had the globalism, size, technology, science, travel, and communications, that we do now?
This is not just more of the same. Scope matters.
To my eyes, what I see, what I’ve seen over the last 40 years,… we’re failing as a species.
February 15th, 2021 at 7:49 am
[…] this series, explain exactly how this works because I’ve already covered that ground. See the Matrix Rotation and Matrix Magic […]
February 22nd, 2021 at 7:48 am
[…] covered matrix-based rotations extensively in two previous posts: Matrix Rotation and Matrix Magic. Refer to those posts for more about rotation using […]
November 11th, 2021 at 10:51 am
[…] rotation. I’m thinking of a version that generates the points, transforms them through a rotation matrix (or using a quaternion) and does the drawing with the transformed points. It’s all just […]
August 9th, 2023 at 7:48 pm
[…] is about matrix transformation, which I sketched out in the previous posts, but as a quick overview (so this post will make some sense), a matrix is just a bunch of […]