 In the last installment I introduced the idea of a transformation matrix — a square matrix that we view as a set of (vertically written) vectors describing a new basis for a transformed space. Points in the original space have the same relationship to the original basis as points in the transformed space have to the transformed basis.
In the last installment I introduced the idea of a transformation matrix — a square matrix that we view as a set of (vertically written) vectors describing a new basis for a transformed space. Points in the original space have the same relationship to the original basis as points in the transformed space have to the transformed basis.
When we left off, I had just introduced the idea of a rotation matrix. Two immediate questions were: How do we create a rotation matrix, and how do we use it. (By extension, how do we create and use any matrix?)
This is where our story resumes…
Quick Review: We see a 2×2 matrix as a pair of (vertical) 2D vectors, each describing a transformed basis vector:
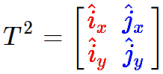
We call the left vector i-hat and the right vector j-hat. We think of them as having originally been aligned with the x and y axes. The actual values of the matrix tell us how i-hat and j-hat transformed.
§
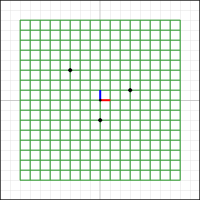
Diagram 1. Initial condition.
For example, diagram 1, our initial condition, features a 16×16 grid (green) superimposed on a 2D space.
The grid has the same size and orientation as the underlying space; it falls squarely on the lighter background grid that represents the default 2D space.
Importantly, the grid is centered on the x and y axes, so the grid’s center lies on the 2D origin point (0,0).
Three black dots mark “points of interest” we’ll follow through any transformation.
The center the grid is marked with a visual representation of i-hat (red) and j-hat (blue).
§

Diagram 2. Transformation!
In diagram 2, I’ve used a matrix to transform all the points of the grid.
Specifically, this matrix:

In the diagram, notice how i-hat and j-hat have moved!
Actually, i-hat is the same — it still points to (1,0), but j-hat now it points to (-1,1), which is a transform from its starting place at (0,1).
Just by looking at their values we know what the matrix has to look like, since it just contains the values of i-hat and j-hat.
More important, notice how, while the black dots have moved (transformed) relative to the underlying space, they have not moved relative to the green grid.
The have the same relation to i-hat and j-hat as they did originally!
§

Diagram 3. Transformation!
In diagram 3, we have another linear transformation. The matrix for it is:
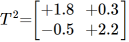
In part to make the point we’re not restricted to integer values. I’ve just been using them to make things simpler to understand.
(For one thing, they make the arrows line up nicely with the grid. You can see how this one doesn’t compared to diagram 2.)
Again, note how the new positions of i-hat and j-hat correspond to the values shown in the matrix — (+1.8,-0.5) and (+0.3,+2.2), respectively.
One crucial point about these transformations: They keep the lines parallel, and the origin never changes.
That is what allows us to move points by re-applying their original coordinates to the new basis.
§
We’re talking two-dimensions here, but everything generalizes to three or more.
The math can get a bit more complicated, but mostly we just add more rows and columns:
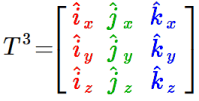
In three dimensions, the addition of the z axis gives us the z basis vector, z-hat, and a new transformed unit vector, k-hat. (We can extend this to as many dimensions as we need.)
The idea is the same: We see a 3×3 matrix as three (vertical) 3D vectors, each describing a transformed basis vector.
We transform points in 3D space the same way we do in 2D space: Their relationship to the original basis vectors transforms them when applied to the transformed basis vectors.
(It’s pretty important that you have read and understood the previous post, because here we go!)
§
Getting back to Flatland and the two questions, I think it’s easier to handle the second question first: How do we use a transformation matrix?
The short form: Given a transformation matrix, T, we transform point P0 to P1 by matrix multiplication:

Which is reminiscent of how we rotate complex numbers by multiplication. In both cases we have an object that rotates points using multiplication.
At a more detailed level, it looks like this:

Which isn’t as bad as it looks. It’s the dreaded matrix multiplication you may have been taught by rote without giving you any insight to the geometry.
It boils down to this:
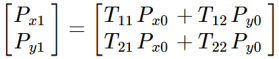
Which is just some multiplying and adding. Nothing to it!
§
Let me take a moment to show you what’s really happening.
We can think of this transformation as i-hat and j-hat (in a matrix) being multiplied by point, P:

We multiply the point’s x value by i-hat and its y value by i-hat. This gives us two vectors that we just add together.
This is how we apply the point’s original coordinate values (which were relative to the original basis) to the transformed basis.
That is the magic!
§
At this point, armed with the above, here’s a video that explains all this brilliantly, visually, and in just ten minutes. If this topic interests you at all, you must watch it!
The channel, 3Blue1Brown, is exceptional and extraordinary. If you have any interest in math, it’s the channel to watch.
This video is part of a series that explores this all in much more detail than I have here. It’s well worth watching.
§
Now we can return to the first question: How do we make a rotation matrix?
The basic template looks like this:

The name, R2z, means that it is a two-dimensional rotation matrix rotating on the z axis. The template is a function; it takes an angle, θ (theta) and returns a matrix of actual values.
To use it, we take the sine and cosine of the angle and plug those values into the matrix as shown in the template.
The example from last post, for instance:

Gives us a 2D transformation matrix which rotates points 15° on the z axis.
§
 To see how this works, for a moment, let’s consider just i-hat.
To see how this works, for a moment, let’s consider just i-hat.
In the template, i-hat has the value (cos θ, sin θ), which might be familiar as “how to draw a circle.”
That is, if we plot x=cos θ and y=sin θ, for all angles θ, we get a circle. (The unit circle.)
So, i-hat just spins (counter-clockwise) around the unit circle, starting at (1,0).
Now let’s consider its sibling, j-hat.
In the template, j-hat has the value (-sin θ, cos θ), which, for one thing, reverses the order from i-hat. For another thing, we’re negating the sine value.

Diagram 4. Rotating hats!
The upshot is that j-hat is rotated 90° ahead of i-hat. It starts at (0,1) and moves counter-clockwise in lockstep with — but ahead of — i-hat.
That’s why a rotation matrix for a rotation of zero degrees ends up being the identity matrix:
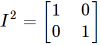
(Because: cos 0°= 1, and sin 0°= 0)
Plugging those values into the template gives us the identity matrix.
Diagram 4 shows the starting and final position of i-hat and j-hat if we apply the 15° rotation matrix from above.
§
Now we are finally ready to start talking about 3D and 4D.
It might seem odd the 2D rotation matrix template I showed you above has ‘z’ as part of its name. There seems no z axis in sight!
Yet, the reality is that the rotation is around the z axis. This becomes more obvious when we consider z axis rotation in 3D:
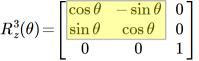
This is very similar to the 2D template. The 2×2 subset in the upper left corner is the same. The only difference is the added right column and added lower row.
That right column is k-hat, the vector that describes how the z axis changes. Above it is set to (0,0,1), which is the z-hat vector, the z basis.
In other words, nothing changes in the z dimension.
Which exactly corresponds to what I said about rotation (if parallel to an axis) not changing the coordinate values for that axis.
Which is why this is rotation around the z axis.
Here are the other two (proper) 3D rotations (along an axis):


In common with Rz, both of these have one vector that’s locked while the other two rotate with sines and cosines.
In all cases, in any dimension, it is the locked vector(s) that names the rotation axis for us.
(As I’ve mentioned, in 4D there are two axes of rotation. This is because there are two locked vectors in a 4D rotation matrix.)
§
I’m going to leave talking much about 4D for future posts. Now I want to return to the idea of proper versus improper rotation.
Proper rotation! [45°]
If you recall, proper rotation doesn’t change the orientation of the parts of a rotating object, it rotates everything in lockstep as a whole.
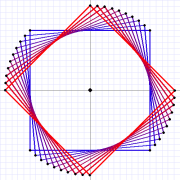
An improper rotation treats the object as if it were reflected in a mirror, it does change the orientation of the parts.
For example, from a 2D perspective, the only proper rotation of a square is on the z axis.
We can imagine a piece of paper spinning on a desktop. It can be upside-down or sideways, but it can’t be backwards.
If we lift the paper, rotate it horizontally (on its x axis) or vertically (on its y axis), then it will be backwards — reversed.

Improper rotation! [80°]
As we do that, to our eyes, at 90°, the paper seems to shrink to a line.
Then it grows in apparent size until, at 180°, it’s full-sized but reversed.
Continue through another 180° and it will shrink to a line and then expand back to full-sized and normal orientation.
This tells us that, improper rotations are actually normal rotations that use an extra dimension.
Paper rotates quite normally (properly) in 3D. It’s only restricted to Rz in 2D.
Note that improper rotations appear to shrink an object through some plane as they rotate them (think of it as the plane of reflection).
In reality the object maintains its size when viewed from the perspective of that extra dimension. The shrinking square maintains its size in 3D even though it seems to shrink to a line in 2D.
§
In the future I’ll consider improper 3D rotations (which invert a cube), as well as that 4D (proper) rotation of a tesseract I’ve been chasing all this time.
Both are examples of the same 4D rotations. For example:
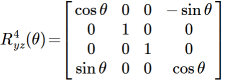
It describes the first mode of rotation in those animated model videos I made. (I hope you can see why it’s named as it is.)
§
Stay transformed, my friends!














April 13th, 2019 at 12:16 pm
Poor unloved post. I know you’re really the heart of the whole series!
February 15th, 2021 at 7:49 am
[…] exactly how this works because I’ve already covered that ground. See the Matrix Rotation and Matrix Magic […]
February 22nd, 2021 at 7:48 am
[…] covered matrix-based rotations extensively in two previous posts: Matrix Rotation and Matrix Magic. Refer to those posts for more about rotation using […]
August 9th, 2023 at 7:48 pm
[…] is about matrix transformation, which I sketched out in the previous posts, but as a quick overview (so this post will make some sense), a matrix is just a bunch of numbers […]