 Back in 2014 I decided that a blog that almost no one reads wasn’t good enough, so I created a blog that no one reads, my computer programming blog, The Hard-Core Coder. (I was afraid the term “hard-core” would attract all sorts of the wrong attention, but apparently those fears were for naught. No one has ever even noticed, let alone commented. Yay?)
Back in 2014 I decided that a blog that almost no one reads wasn’t good enough, so I created a blog that no one reads, my computer programming blog, The Hard-Core Coder. (I was afraid the term “hard-core” would attract all sorts of the wrong attention, but apparently those fears were for naught. No one has ever even noticed, let alone commented. Yay?)
In the seven years since, I’ve only published 83 posts, so the lack of traffic or followers isn’t too surprising. (Lately I’ve been trying to devote more time to it.) There is also that the topic matter is usually fairly arcane.
But not always. For instance, today’s post about Unicode.
Although, to be honest, that post is written for computer users who’ve gotten their hands dirty dealing with code page or characters set issues, so it’s still a bit esoteric and technical. Here I thought I’d point to that post for those interested and provide a less technical overview of Unicode.
Because, whether you realize it or not, it’s not just something very important for the internet but something you probably use every day (assuming you use a computer, tablet, or phone, every day).
§
Unicode is the standard that computers worldwide use to represent text. The goal of Unicode is to include every alphabet in the world, including some historical ones. Unicode also includes lots of special characters (such as ℜ, ∞, ∅, ⇔, ⊗), and it includes the emoji set (😎🧛🏼♀️🎃🍕🚓💥).
So you can perhaps see its importance. Every text, every email, every webpage; they all use the Unicode standard. For most users Unicode is generally something they don’t ever have to think about, but there is one situation where it’s helpful to understand what’s going on.
If you’ve ever had your text change from this:
I didn’t imagine that!
To this (what happened to that nice apostrophe?):
I didn’t imagine that!
Or rather than the apostrophe, perhaps it was the quotes:
He asked, ‟Did you find it?”
And they turned into something like:
He asked, ‟Did you find it?”
In both cases, you’ve run afoul of a (very common) Unicode issue — specifically one involving UTF-8, the most common form of Unicode most users encounter. It usually happens when pasting copied text into something that doesn’t recognize the text as UTF-8, but as some form of ASCII (a much older way of encoding text).
I’ll give you a couple of solutions after I’ve made you read the rest of the post.
§
So what, from a casual user’s point of view, is Unicode? I said above that it seeks to include every alphabet in the world (and a lot more). As succinctly as possible (in less than 25 words):
Unicode seeks to map all glyphs of all languages to unique integer code points along with various 32-bit, 16-bit and 8-bit physical encodings.
It actually does say it all, although it might take a bit of unpacking.
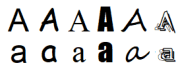
Versions of the ‘A’ glyph.
Firstly, a glyph is the visual representation of a letter (or, in some languages, part of one). There is, on the one hand, the letter A as an abstraction with no physical representation — it’s simply the first letter of the English alphabet.
On the other hand, is the letter’s representation on the page or screen, which depends on its font (as in the examples of A shown here). Unicode does not concern itself with fonts, only with the abstraction. As far as Unicode is concerned, there is only one glyph for the letter A (and one for a — Unicode does recognize case, because that’s a formal part of language).
While we don’t see it in English, in other languages the letter A can also represent as À, Á, Â, Ã, Å, Ā, or others, and these are all distinct glyphs to Unicode (likewise their lowercase versions).
Secondly, a code point is just a unique number assigned to a glyph. Code points start at zero and count upwards. They are not necessarily contiguous — there are ranges of code points with no glyphs (yet) assigned. Unicode code points currently go up to just over two million.
Finally, the physical encodings in package sizes used by nearly all modern computing devices. Unicode currently is a 21-bit standard (those two million plus code points), so while it fits comfortably in 32 bits, it requires some gyrations to fit in 16 or 8. That’s what standards like UTF-8 are for.
§
Getting a bit more detailed, Unicode divides into four basic sections, two of them abstract, two of them concrete.
Firstly, there is the Abstract Character Repertoire (ACR), which is the collection of glyphs Unicode includes. There is no order other than within an alphabet or character set that has one. All the special characters and emojis are included in the ACR. Note that these entries are just text — for instance: “LATIN CAPITAL LETTER A” or “FACE WITH TEARS OF JOY”
Secondly, there is the Coded Character Set (CCS), which is also abstract, but bridges towards a concrete implementation. The CCS is the set of non-negative integers, the code points, assigned to each member of the ACR. Note that these entries make no reference to physical size — bits, let alone bytes.
[See the Unicode Code Charts for listings of the ACR-CCS “scripts” (language related groups of glyphs).]
Thirdly, there are the Character Encoding Forms (CEF), and now the rubber starts to meet the road. These describe how the CCS code points fit into physical machine widths of 32, 16, and 8 bits. A CEF defines how a machine or database handles Unicode internally.
Lastly, there are the Character Encoding Schemes (CES), which map the CCS code points to octets (bytes). These schemes are important for byte-based storage (e.g. disks) and especially for the internet, which is based on octets. UTF-8 is a CES — probably the most important and common one. Most webpages use UTF-8.
[See Unicode Technical Report #17 for a more detailed account of these four sections]
§ §
The USA never needed much more than ASCII (the American Standard Code for Information Interchange), but much of the rest of the world doesn’t have character sets that fit into 8-bit bytes (ASCII does with room to spare).
Asian languages, however, have large character sets — thousands, if not tens of thousands, of distinct glyphs. Historically, countries found their own ways of dealing with this (transmission and storage have long been byte-based), and there existed a metaphoric (but very real) Tower of Babel situation that made life hell for administrators and users.
Unicode embraces all the glyphs of the world. Problem at long last solved.
§
As for the UTF-8 issues above, there are two possible solutions, depending on where the problem is happening.
The fancy apostrophe and quote characters aren’t ASCII. Before Unicode they were defined in different versions of extended-ASCII (and not always with the same encoding). Pasting the UTF-8 sequences that encode those fancy characters is interpreted as extended ASCII (see my other post for details).
The solution is to either edit the pasted text to restore the fancy characters or replace those fancy characters in the original with their plain brown ASCII versions.
In an HTML context, one can also use HTML codes such as “ (left double-quote) and ” (right double-quote). The fancy apostrophe is ’ (right single-quote). One can also use the &#….; form to insert any Unicode character given its code point.
Since the problem usually happens when pasting nicely formatted text (say from a Word document) to some web-based source (comment box or whatever), either solution may be helpful.
§ §
This is the month of giving thanks, and I’m hardly the first to give thanks for Unicode. It really has made my life as a computer programmer (and as a user) a lot better. Standards are sometimes more of a pain than a blessing, but I can’t say I’ve ever found any downside in Unicode.
Stay Unicoded, my friends! Go forth and spread beauty and light.
∇














November 15th, 2021 at 1:41 pm
Here’s a video (from 2019) that more or less inspired this post:
(I’ve had the link sitting in my queue since then!)
November 15th, 2021 at 1:56 pm
Heh, this is the 1000th post for the Main Index and the beginning of a new Cycle! 😀
November 15th, 2021 at 2:01 pm
(There are 187 posts not in the Main Index. They’re listed in either the Sidebands, Brain Bubbles, or Special Relativity indexes.)
November 15th, 2021 at 5:12 pm
I never had to get into the intricacies of Unicode when I was coding, and now that I’m on the dark side, I probably never will. I do seem to frequently observe the consequence of violating one of the central commandments of transmitting text data, “Thou shalt escape thy non-alphanumeric characters.”
Congratulations on hitting 1000 again! You know a lot more about the stats on your blog than I do about mine.
November 15th, 2021 at 8:28 pm
Heh, that’s just because I maintain those Indexes. (And I do that just because I like an easy way to find an old post.)
At work I did a lot of J2EE programming, so I did have to deal with Unicode issues. And there seemed no end of situations were people were pasting from MS documents to web-based contexts that didn’t recognize UTF-8 for what it was. Even my hobby coding has enough web-based stuff that I have to deal with it. Parsing XML can also encounter issues.
It has gotten better and much more transparent. I wrote some RSS code that had to jump through some hoops to turn the XML content, which Python’s http module treats as byte strings, into printable text strings. When I upgraded from Python 2.7 to 3.7 that code broke — started printing the UTF-8 sequences, and I couldn’t seem to find the right hoops to jump through to fix it. I finally realized I had to remove the hoops; Python didn’t need them anymore.
Text editors, compilers, systems in general have all gotten better, but I think that commandment is still a good idea. I wish WordPress wasn’t so aggressive in converting HTML character codes into their Unicode equivalents.
November 16th, 2021 at 7:10 am
Ugh. The MS document comment brings back memories of an application I once had to support where executives uploaded their annual reports to a web site. Most of them did them in Word, and the mess that Word’s html export feature made led to us spending a lot of time fixing their document so it would display right on the site. Not happy memories.
I’m blissfully ignorant of WordPress’ Unicode behavior. Hope I never have to deal with it.
November 16th, 2021 at 8:27 am
Oh, I remember the MS export as HTML feature and what awful HTML it created. We had people who tried to create web pages that way, or who would write an email in Word and copy-paste it into their email (Lotus Notes, which was a horror show all on its own on so many counts). All ancient memories thanks to retirement.
I think it isn’t WP’s Unicode handing so much as their HTML handling. As you know they massage incoming HTML rather severely — stripping out a number of tags and all the CSS. (The damned Reader is especially aggressive that way.) They also convert HTML character codes — the little sequences that begin with an ampersand — to their actual (Unicode) characters.
It matters to me because my final step with posts is to go into the HTML editor, copy the entire text, paste it into my text editor, run a macro that wraps the paragraphs (just text separated by blank lines) in P tags (and removes the blank lines). Unfortunately, my editor is one of those softwares that doesn’t expect UTF-8 being pasted in, so it mangles actual Unicode characters requiring another step of fixing those up.
I do this as a defensive measure against the damned Reader, which often is blind to the very mechanism WP uses for paragraphing (the aforementioned blank lines). I just had to go fix this post because, with all the Unicode characters in this post, I did that process by hand and missed the middle section. I noticed in the reader that the entire middle section was shown as one paragraph. [sigh]
I hate the WordPress Reader so much!
One of these days I need to vent my spleen and write (nastily) about the damned Reader. I’ve seen a lot of other posts with obviously merged paragraphs, so I thought I’d write about how to fix that, although it does require getting one’s hands dirty.
November 16th, 2021 at 8:55 am
Your comment about Lotus Notes is funny, because that app I mentioned was actually a Domino app. This was during a period when our shop always favored IBM, no matter how miserable their product was, and we were forced to do all web apps in Domino (shudder). And it very much was a horror show. We spent most of our time tricking Domino into doing something that would have been trivial with a straight CGI script.
I’m glad I haven’t hit those issues with the Reader. It’s very much not my preferred way of reading posts, but I know it is for a lot of people. Collapsing paragraphs would really bother me, because in online writing, paragraph size is a key tool for readability.
I sometimes wonder if people are doing something similar to what you do when writing comments. Occasionally I get comments that are 200 word walls of text, and it seems hard to believe the person meant to do that. I know I sometimes type long comments out in a Google Doc, just because it’s being saved while I work on it, and I’ve occasionally had formatting issues when I pasted it into WordPress, although they’re usually evident and can be corrected before submitting, assuming I’m not in too much of a hurry to proof it.
November 16th, 2021 at 10:16 am
I vaguely remember Domino. Mostly I vaguely remember thinking, “WTF?!” 😮 We also were all in on Lotus Notes (and on IBM ThinkPads). It was the corporate email system, and just about everyone hated it. We were also way into the automation — there was a massive document version control system they had (Umbrella?) that eventually died under its own bloat. Lotus Notes was definitely one of the most annoying aspects of my daily corporate life.
I don’t use the Reader that much for reading posts, but it’s a little too handy for following comments. I does make it easy to see new comments on posts you follow. I no longer bother with email notifications about new posts or comments. It also allows a direct reply to a comment even if the allowed level of indenting doesn’t give that comment a reply link on the webpage. I do like that feature.
But that’s about it. The ability to see new comments and the ability to reply directly to any comment. I pretty much loath every other aspect of the damn thing. (They’ve added a new wrinkle that I have mixed feelings about: The menu on the left, the Followed Sites link used to just give you the page listing recent posts of blogs you follow. Now it opens a list of all the blogs you follow listed in order of most recent publish. So getting to the “All” takes two clicks that used to take one. The list is a bit interesting to have, but I can’t figure out what the numbers mean.)
I don’t know why the collapsing paragraphs thing doesn’t outrage more people. I’ve noticed a number of other posts that I’m sure had more line breaks than being shown. I commented on their blog, letting the author know, and the response was basically that they didn’t care about the Reader and weren’t interested in trying to fix the problem (or in complaining to WP). If that’s a common attitude, no wonder.
I think I will write a rant post about the problem. Then I could just link to that when I notice the problem on other blogs.
I think some people just haven’t figured out putting a blank line between paragraphs. I get some comments that have obvious paragraphing — they hit the Enter key — but no blank line between. (I often fix those by adding blank lines for them.) In other cases, it might be the WP bug that merges paragraphs.
What’s pathetic is that I think this is, in part, due to that Block Editor. Their technology seems to assume it and Classic Editor is more and more of a special case. I understand the BE puts each paragraph in a separate block (which seems like a nightmare to me), so apparently their software no longer is very good at spotting blank lines.
But that’s what every comment requires. The comment boxes don’t use the BE, so WP has to have the ability to properly process input text, and that has apparently slipped through their fingers. When I use the Reader to view a post and comment at the bottom, the resulting comment always shows up as a single merged paragraph. But back out of the page, refresh, come back, and the paragraphs are (usually) back. Maybe that’s not working for some of the comments you’ve seen.
Enter a comment on the Conversations side of the Reader, and that doesn’t happen (which I see as defective design). Only on the Following side. And, of course, never on the actual webpage.
Yeah,… I should really write that post… get it out of my system! (Complaining to WP has done zero.)
November 16th, 2021 at 5:05 pm
We actually still have our Domino environment up. No one has Notes email anymore, but all those damn apps they made us develop are now legacy apps. We’re beginning an epic project to replace our student information system, which hopefully will lead to the decommissioning of both our mainframe and Domino environment. But that’s still four years away, and in the meantime I somehow got stuck with trying to figure out how to upgrade the environment so we can hold it together until then. 😡
I didn’t realize the Followed Sites thing had changed in Reader. That is kind of a nice feature.
But yeah, those numbers are a little enigmatic. From what I can see, they sometimes refer to the number of posts made in the last year, that the Reader doesn’t do it’s fading thing on. I say sometimes because often it doesn’t. My site shows 25, but I have a lot more posts than that in the last year. WAIT! I think they refer to the number of posts done with the Classic editor. Weird. So is it broken for posts done with Block?
The Block Editor does put every paragraph in its own block. That is annoying, but you get used to it. The only headache is when I want to select text spanning multiple paragraphs. I can do it, but it will select the entire paragraph of each paragraph included. The only way around it is to do separate selects, or combine the paragraphs and then do the selection.
More annoying is that the bug where the editor displays text small has come back, and WP’s only solution is for me to upgrade my theme again. Given how painful that was, it will take more than that to make me do it again. For now, I just use the browser zoom while editing and hope it goes away again.
You should do the rant post and get it out of your system, at least for a while.
November 16th, 2021 at 7:34 pm
Oof, legacy aps. I feel for ya. I know full well what a bane they can be. I worked for an international corporation that’s been around for many decades, and they had some really ancient stuff running on mainframes, too. One of those no-good-options situations. One more bullet point on the “should I retire” chart!
For me the Followed Sites list shows 105 for your blog, 34 for Logos con carne and only 1 for The Hard-Core Coder. And I’m not sure I’ve seen them change in a while. (At least I’ve noted them here as a reference for later.) As you say, they sometimes seem to refer to how many posts aren’t grayed out, but it’s way off in some cases. I wonder if it was created and never updated?
Why would your theme matter to the Block Editor? I suppose column width might be nice, but what gyration causes it to make the text small? Have you tried using your browser’s Inspector to at least see where the small size is coming from? It might give you an information arrow to shoot back at WP.
Yeah, I think maybe I will do a post…
November 16th, 2021 at 8:30 pm
Yeah, Domino and a bunch of other projects on the one side, inflation on the other. Hopefully the supply chains unsnarl fast enough to taper inflation. At least I don’t have to personally work on Domino, just figure out a strategy for getting it done.
So the numbers are relative to each user. Interesting. I thought about unread count, but read a few and didn’t see any difference, unless it’s something that doesn’t update right away. Ok, well, maybe it’s just a coincidence that the number for my blog that displays to me matches the classic editor posts. 🤨
I’m not sure how or why, but your theme matters to both the classic and block editor. Every time I’ve changed themes, the font in the editor changed. (It was actually another reason I disliked the second to last theme I used. It caused a lightweight hard to read font to show in the editor (classic at the time).) Now, why a theme with fairly large font leads to an editor with small font? Search me. I haven’t tried inspecting it, since I don’t have any way to change it. The WP developers seem to understand the relationship.
November 17th, 2021 at 10:01 am
Yeah, it’s always better telling someone else to do the work than having to do it yourself. (Although, flip side, I’ve sometimes often that means it doesn’t get done as well as I’d like. One of the reasons I retired early was I was put in the position of designing and then directing the work of others, and, well, I really found out the meaning of “it’s so hard to get good help these days.”)
I’m going to keep an eye on those numbers. (I wonder if there’s some documentation somewhere that would explain them.) As of this morning I’ve noticed a new “behavior” (bug?) in the Conversations side of the Reader. It no longer shows the most recent comments. Those are hidden behind those “Load previous comment from …” links. It now seems random which comments are shown and which are hidden, but all the most recent ones are hidden now.
It’s hard not to get very down in my opinion of on WP tech staff. (But as I just said, I came to realize that truly skilled programmers are actually fairly rare beasts. Rank amateurs abound, though.)
Now that I think of it, the Classic Editor does have a different font in The Hard-Core Coder than in Logo con carne. I think the former even imposes a column width, although the latter doesn’t. I did a bit of tweaking on the CSS of both blogs and realized the CSS names are different between styles, too. On the programming blog, post text is in a .post-entry class, but on this blog there are nested .post and .entry classes. To me that speaks to a lack of unification in their designs.
I’m working on that post about paragraphs. Way it’s going I may have to write a separate about the ills of the Reader. This one is already over 1600 words because I have to explain HTML a bit to explain the problem.
November 17th, 2021 at 11:51 am
I’ve been a manager for almost twenty years now (actually my second stint as manager since I was also one right out of school). You eventually get past the “they’re not doing it right” impulse and just look to see if they’re doing it a good way rather than “the right” way. But definitely not an easy transition, and not for everybody.
I noticed today that the Reader site numbers are computed on the fly. (It happens very fast, so it’s easy to miss.) So whatever it’s doing, it’s doing it dynamically. I did look for documentation but wasn’t able to find anything. If it exists, they haven’t made it easy to find.
One of the reasons I don’t usually use the Conversations tab is it doesn’t do a good job on predicting which parts of a thread I’m interested in. Not that the email notification is perfect by any stretch. It sends everything in a thread. I have mail rules set up to fish out the comments that are addressed to me, but I still sometimes miss interesting conversations on other people’s blogs.
Yeah, the different ways of doing CSS is one of the headaches when switching themes. I almost always have to do some CSS tweaking, and every theme seems to do it differently. There are families of themes which do it similarly, but that’s about it.
I think the end game of the block editor is eventually to allow us to design our own theme without programming. Considering I mostly want the theme to just stay out of my way, I’m hoping that makes things better.
November 17th, 2021 at 12:11 pm
I realized a long time ago I was a worker bee, that I had no interest in management. Fortunately, The Company had a technical track for advancement as well as the usual management one. (We had a lot of scientists and technicians working in various labs and factories.) I have a certain envy for construction workers. I could have gone that way myself. I like building things. I just do it with bytes rather than lumber. 🙂
Today the Conversations section has lost its mind, but I know what you mean about parts of the conversation. It normally only shows the most recent three or so comments. If I want to dig back into the conversation I have to click those “Load previous …” links to expose it. Sometimes I just keep clicking the top one until the whole conversation is exposed.
There’s a link to another guy’s blog post in the comments of the post I just published. It makes me wonder if the BE might be the one to eventually go away. (I haven’t noticed people complaining about the huge typing lag times he mentions, though. Have you found typing in the BE slower?)
November 17th, 2021 at 1:08 pm
I haven’t particularly noticed typing to be slower in the BE, and I’ve used it on five year old machines. Of course, if someone’s using it on something older, or some other kind of device with less processor or memory, I could see it possibly making a difference. But not an issue I’ve run into.
For me, the biggest issue with the BE was getting it configured right. The big one was setting the toolbar to only display at the top rather than on top of each block, where it was perpetually in the way. There were also a few others to just basically make it look more like an editor rather than a design tool, although I’m drawing a blank on those now.
Just now, looking at the options, I noticed there’s an option to display things according to your theme, which was turned on. Just turned it off, and now the text is easy to read again. Yay! (It actually looks more like my theme without that setting.) Why the !@#$% didn’t support tell me about this?!?
November 17th, 2021 at 2:41 pm
I do wonder sometimes if COVID caused quality hits in a lot of places. I used to be very impressed by WP, but lately not so much. I’m glad you found a fix. That sounded like a real drag.
I really should get to know the BE more so I don’t get caught off-guard if the CE goes away. I intended to start using it on my other blog, but when I did, something about how it acted really put me off my feed. From what you’re saying, perhaps there are options that might reduce the pain. (Right now I’m pretty focused on just writing posts, though.)
The HTML editor tab in the CE has a, I assume, buggy mode where it suddenly bogs down to the point of being almost unusable. Hasn’t happened to me in a long time, so maybe they fixed it. I learned it was best to return to visual, save the post, get out of the editor, and even close the browser.
From what that post describes, it sounds like the BE can be in a situation where it has to move all the downstream blocks, which is what bogs it down. I suppose it depends on how many and what kind.
November 17th, 2021 at 3:49 pm
On COVID and WP, I don’t know. Some of my issues, like the missing posts in Reader, started before COVID. I didn’t actually get actionable advice from them on it until during the lockdown. (Although that might have been just a factor of finally connecting with a support person who understands the system.) And I find their theme offerings maddeningly limited. That’s always been the case, but it seems worse now.
Yeah, with the BE, it felt like the writing was on the wall, so I just started doing posts in it to see if I could get used to it. I figured if I couldn’t and the CE went away, I might have to find somewhere else to blog, or go self hosted. Fortunately, with a few setting adjustments in each editing session, it got tolerable pretty quickly. There are things I still don’t like about it, but that’s true with any tool.
On moving blocks, it might be significant that most of my posts only have text blocks, with an occasional quotation one (still text). Maybe if I had a lot of imagery or other fancy stuff, it might bog down more. Or if I had longer posts, although I’ve done a few closing in on 2000 words with no noticeable problems.
November 17th, 2021 at 7:10 pm
I just meant the COVID might have impacted their support line. You complained that you weren’t told about a simple fix — which I agree is pretty unforgivable. Help line should certainly know about the effects of options. That should have been a quick call. My own contacts with WP support the last few years also have been less than satisfactory in contrast with how it was long ago.
What you say about text blocks makes sense. They’re a lot easier to move around. You keep your posts short enough — maybe a couple or few dozen paragraphs? — that the system might not have to work so hard.
November 17th, 2021 at 10:37 am
[…] it. Compare how it looks in the Reader versus my website. I did the same thing accidentally in the previous post, and that part got […]
June 12th, 2022 at 4:20 pm
[…] intended to be secure in any sense but are only protocols that map some form of data to numbers. Unicode, for instance, maps all the glyphs from all the common languages of the world, plus many special […]
November 24th, 2023 at 2:24 pm
[…] Getting back the giving thanks thing, science-y geeks like the opportunity to point out a cool science-y thing we should all be thankful for. Like atoms or gravity. I jumped on the wagon (we don’t have an official band, yet) a couple of years ago highlighting Unicode as something we should all give a moment of thanks for. […]
November 28th, 2024 at 12:40 pm
[…] thanks for gravity and light. I’ve written such posts myself. One year it was patterns, another it was Unicode. Last year it was a bit of a riff on […]
February 16th, 2026 at 9:16 am
[…] strings are Unicode and many contain any valid Unicode character including emojis. [See this LCC post for a general overview or this HCC post for a more technical […]