Back in 2014 I decided that a blog that almost no one reads wasn’t good enough, so I created a blog that no one reads, my computer programming blog, The Hard-Core Coder. (I was afraid the term “hard-core” would attract all sorts of the wrong attention, but apparently those fears were for naught. No one has ever even noticed, let alone commented. Yay?)
Back in 2014 I decided that a blog that almost no one reads wasn’t good enough, so I created a blog that no one reads, my computer programming blog, The Hard-Core Coder. (I was afraid the term “hard-core” would attract all sorts of the wrong attention, but apparently those fears were for naught. No one has ever even noticed, let alone commented. Yay?)
In the seven years since, I’ve only published 83 posts, so the lack of traffic or followers isn’t too surprising. (Lately I’ve been trying to devote more time to it.) There is also that the topic matter is usually fairly arcane.
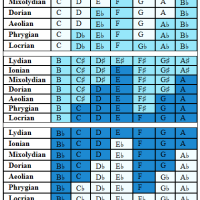
But not always. For instance, today’s post about Unicode.