 Over the last two days I’ve written about a way of viewing words, sentences, even entire books, as single (very large) numbers. We do that by treating the characters in the string as “digits” in a number system we define. Technically speaking, we interpret the string as a number written in some large radix.
Over the last two days I’ve written about a way of viewing words, sentences, even entire books, as single (very large) numbers. We do that by treating the characters in the string as “digits” in a number system we define. Technically speaking, we interpret the string as a number written in some large radix.
This is actually what we do every time we look at a written number. For example, we interpret the four-character text string “2013” as representing the numeric value two-thousand-and-thirteen. We do this easily, because we’ve grown up with the base 10 number system, decimal. The systems I’ve written about simply extend the concept.
Today, as a Sideband, I thought I’d get into some of the more technical details.
 Some of you are probably thinking, “Now he’s going to get technical?!”
Some of you are probably thinking, “Now he’s going to get technical?!”
I realize that the last two articles were indeed somewhat technical, especially if the topic is new to you or if you aren’t used to thinking about math.
But I really just scratched the surface to explain the topic.
For those new to it, I hope you came away with the understanding that any string of text — in a sense — is a number. It is a unique combination of symbols, a frozen pattern that is a single data point in a vast landscape of data points (other texts). If you got that much, we’re good.
For those who want to dig deeper, keep reading!
Number Bases

Seriously, that is the only reason we count by tens.
If we had six fingers in each hand, we’d count by twelves, and it would feel just as natural.
(In fact, there are some nice things about base 12, due to twelve being divisible into halves, thirds, quarters and sixths. Compare that to ten, which can be divided only in halves and fifths.)
Some ancient societies did have different number bases — the Mayans used base 20.
As I understand it, they used their fingers plus the large joints, which gave them 20. (Your fingers—other than your thumb—have two joints, but the thumb has just one.)
The Sumerians did use all finger joints but excluded the thumbs entirely. This allowed them to count to 12 using the fingers of one hand.

Thumbs are place holders!
[Someday I’ll teach you to count to 32 using the fingers of one hand and to over 1000 using the fingers of both hands. (One word: binary!)]
What’s really key here is that anything you can do in one number system, you can do in any number system.
(There is a caveat having to do with fractional notation. I won’t get into it now but think about how you’d write out the numbers for 1/3 and 1/10 in decimal versus ternary.)
Positional Notation Multiplication Factors

 But there is a very simple way to calculate the factor for any position in any base.
But there is a very simple way to calculate the factor for any position in any base.
Just raise the base (“B”) to the power of the digit position (starting with zero and counting right to left).
The first (right-most) position in any base, is always one. That’s because any number to the power of zero is — by definition — one. The next position will always be the base, because any number to the power of one is that number.
Number System Digits

hexadecimal
Number systems with a base greater than ten need new symbols.
Computer programmers often use hexadecimal (base 16), which requires six new symbols. The standard protocol is to use “A” through “F” (thus in hexadecimal, you count: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F).
The idea of using the alphabet works all the way up to base 36, which counts from “0” all the way up to “Z”.
In our “L” systems (the “L” stands for “letter,” by the way), we started with the basic alphabet as our digit symbols — the basic L26 system.
Next, we shifted to using both UPPER- and lower-case letters (plus a space for the zero). Then we added the digits and some symbols to end up with the L80 system.
I left off yesterday with the suggestion that we needed something bigger than L80 for a really universal system.
Using L80 was entirely arbitrary, and it does allow only a handful of punctuation symbols. There’s no reason we can’t define an L90 or L100 system to include more.
We just need to decide on a set of symbols (letters, digits, punctuation, extras) and then assign numeric values to them.
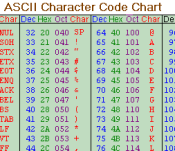 There is a natural candidate for a set of symbols that is inclusive enough that it can be applied to just about any text, so long as that text uses the standard Latin alphabet.
There is a natural candidate for a set of symbols that is inclusive enough that it can be applied to just about any text, so long as that text uses the standard Latin alphabet.
That candidate is the computer encoding scheme known as ASCII (“ass-key”). Up until the modern era of international computing, just about all personal computers used ASCII to encode text. It’s used in network transmissions, emails, webpages, pretty much everything.
However, using standard (i.e. 7-bit) ASCII gives an L128 scheme, which means the factors will be huge (to the tune of: 1, 128, 16384, 2097152…). In L128, short four-character words will have values in excess of two million.
The next jump might be to extended ASCII.
Many manufacturers took advantage of the fact that standard ASCII is a 7-bit encoding, whereas computers processed data in 8-bit chucks (the famous “byte“).
By defining an 8-bit encoding that used standard ASCII as a subset, they got the 128 standard ASCII characters as normal, but got another 128 extended characters (sometimes called “upper ASCII”).

CP-1252
Of course, different manufacturers defined upper ASCII differently depending on their needs.
One important scheme remains. Defined by IBM for the PC, Code Page 1252 is still in wide use today (causing a degree of grief where it collides with Unicode, but that’s a separate post).
So, we could use CP-1252, which includes characters necessary for some European languages, such as German, Spanish and French.
For example, CP-1252 includes: “á”, “ê”, “ñ”, “ö” and “ç”.
Using such an 8-bit encoding puts us in an L256 scheme, which will have truly gigantic factors, but it allows us to generate numbers for texts in many other languages.
How gigantic are the factors in L256?
The factors start out: 1, 256, 65536, 16777216… In this scheme, four-character words have values that begin at 16 million plus! The smallest possible five-character word has the value 1,099,511,627,775!
And we’re still excluding all of Asia and the Middle East (and Elvish Runes)!

Elvish Runes!
Just as ASCII was a natural candidate for encoding English text, there is a natural candidate for encoding text in (nearly) any language.
It’s called Unicode, and it seeks to be a universal character set of all extant languages (and some dead ones). It even includes musical symbols, “Wingdings” and Tolkien’s Elvish Runes!
The problem with Unicode is that it’s huge.
The latest version has over 100,000 symbols, and its theoretical total address space is over two million. So, we’re talking something like an L125000 system at least. (You don’t even wanna know what those factors look like!)
If I had to implement such a thing, I’d go with the Unicode UTF-8 encoding, which shoehorns Unicode into an 8-bit scheme.
That allows me to just use L256 (which is bad enough). And as I pointed out yesterday, the L-scheme doesn’t really matter. What matters is the understanding that any text can be viewed as a single number.
§
 For the Pythonistas in the crowd, I leave you today with some Python code that implements L26, L27 and L80.
For the Pythonistas in the crowd, I leave you today with some Python code that implements L26, L27 and L80.
Enjoy!
(Implementing an L128 or L256 system is an exercise left to the clever reader.)
L26
002| s = reversed(_s.upper())
003| b = ord(‘A’) – 1
004| a = []
005| for d,ch in enumerate(s):
006| f = pow(26,d)
007| n = 0 if ch == ‘Z’ else (ord(ch) – b)
008| t = (ch, n, f, n*f)
009| a.append(t)
010| for t in reversed(a):
011| print ‘[%s] %d * %d = %d’ % t
012| v = reduce(lambda acc,x: acc + x[3], a, 0)
013| print ‘%s = %d’ % (_s, v)
014| return (v, a)
015|
L27
002| s = reversed(_s.upper())
003| b = ord(‘A’)
004| a = []
005| for d,ch in enumerate(s):
006| f = pow(27,d)
007| n = 0 if ch == ‘ ‘ else (ord(ch) – b)
008| t = (ch, n, f, n*f)
009| a.append(t)
010| for t in reversed(a):
011| print ‘[%s] %d * %d = %d’ % t
012| v = reduce(lambda acc,x: acc + x[3], a, 0)
013| print ‘%s = %d’ % (_s, v)
014| return (v, a)
015|
L80
002| cs = ‘0…9 ABC…XYZabc…xyz.,;:!?”@#$%&*()-_’
003| s = reversed(_s)
004| a = []
005| for d,ch in enumerate(s):
006| f = pow(80,d)
007| n = cs.index(ch)
008| t = (ch, n, f, n*f)
009| a.append(t)
010| for t in reversed(a):
011| print ‘[%s] %d * %d = %d’ % t
012| v = reduce(lambda acc,x: acc + x[3], a, 0)
013| print ‘%s = %d’ % (_s, v)
014| return (v, a)
015|












And what do you think?