Category Archives: Computers
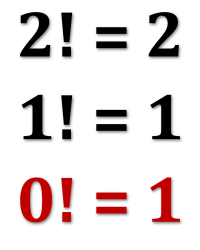 Recently, I learned an interesting new math trick involving what are known as dual numbers. These are compound numbers similar in form to complex numbers but with a different kind of “magic” element enabling their behavior.
Recently, I learned an interesting new math trick involving what are known as dual numbers. These are compound numbers similar in form to complex numbers but with a different kind of “magic” element enabling their behavior.
What makes them interesting to people like me is the surprising way they provide a fast and easy technique for software to generate the derivative of a given function.
As an unrelated bonus, a simple explanation of why zero-factorial is equal to one rather than zero (which might seem more intuitive).
Continue reading
1 Comment | tags: computer programming, derivatives, dual numbers | posted in Computers, Math
 One of the Substack blogs I follow, A Piece of the Pi by Richard Green, is almost ideal from my point of view because it features articles that interest me but only — at most — a few a month (so I needn’t strain to keep up).
One of the Substack blogs I follow, A Piece of the Pi by Richard Green, is almost ideal from my point of view because it features articles that interest me but only — at most — a few a month (so I needn’t strain to keep up).
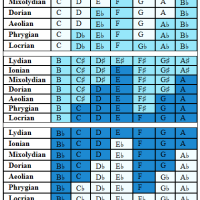
Which matters because keeping up with dozens of science and math blogs, video channels, and occasional papers takes considerable time away from various hobby projects. But sometimes (and this is the third time Mr. Green has done this) something captures my imagination and sends me off on a tangent.
The results often seem worth sharing, and this is no exception. The delight here is that such a simple idea results in a variety of interesting patterns.
Continue reading
6 Comments | tags: computer generated images, Mary Everest Boole, Python | posted in Computers, Math
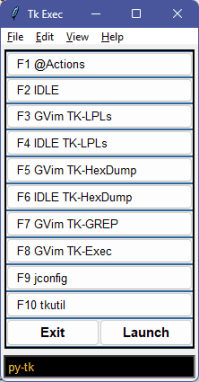 A few posts ago I wrote that for “two weeks I’ve indulged in intense 12+ hour days on a self-education project in Python and its Tk module.” The end result of the binge is seven new apps (so far; more to come) and a good starting grasp of how to make some fairly decent windowing apps in Microsoft Windows using out-of-the-box Python.
A few posts ago I wrote that for “two weeks I’ve indulged in intense 12+ hour days on a self-education project in Python and its Tk module.” The end result of the binge is seven new apps (so far; more to come) and a good starting grasp of how to make some fairly decent windowing apps in Microsoft Windows using out-of-the-box Python.
More concretely, my “tk” project folder has 14 Python files with over 9,000 lines of code (367,000+ characters). That’s what remains. I didn’t save the many false starts, tests, and trials. Suffice to say I probably wrote close to twice as much code.
This post is “Dear Diary” entry for documenting the progress, the fun, and the frustration. It may not be terribly interesting for anyone else, but I learned a lot and (ultimately) really enjoyed the experience. And it’s nice to find out that this ancient dog can still learn new tricks.
Continue reading
15 Comments | tags: grep, hex dump, POV-Ray, Python, Thanksgiving, tkinter | posted in Computers, Life, Writing
 This post begins with a bit of what I see as good news. We’re exactly one month away from Winter Solstice — December 21st at 15:03 UTC. That’s 9:03 AM USA Central Time, and I set posts to publish at 9:14 AM, so by the time you read this, it’s just under a month away.
This post begins with a bit of what I see as good news. We’re exactly one month away from Winter Solstice — December 21st at 15:03 UTC. That’s 9:03 AM USA Central Time, and I set posts to publish at 9:14 AM, so by the time you read this, it’s just under a month away.
Cue regular Solstice-Equinox reminder that the day-length changes very slowly at the Solstices and very rapidly at the Equinoxes [cue regular link: Solar Derivative].
Until then, here’s another edition of Friday Notes.
Continue reading
5 Comments | tags: AI, Bentley, eagle, equinox, Python, snow, Solstice, squirrel, weather | posted in Computers, Friday Notes, Math
 Maybe this is on me; maybe I lack proficiency with English grammar. That’s always possible. I certainly have no pretension of being a grammarian, but I like to believe I have some grasp of it. In any event, lately I’ve found myself bemused by the Microsoft grammarian embedded in Windows™.
Maybe this is on me; maybe I lack proficiency with English grammar. That’s always possible. I certainly have no pretension of being a grammarian, but I like to believe I have some grasp of it. In any event, lately I’ve found myself bemused by the Microsoft grammarian embedded in Windows™.
It seems to have gotten weirder. That, too, could be on me; maybe I just don’t remember it being this amusing (which is one way to put it). In the past, even though we sometimes disagreed, I seem to remember it as being more useful than distracting.
But recently it seems to have become a lot less helpful.
Continue reading
7 Comments | tags: AI, grammar, Microsoft Windows | posted in Computers, Writing
As I posted Tuesday, I finished the software for my virtual CPU on Monday, but now I’ve finished the most important part: the project graphic.

Now that I’m done, the project is obsolete, and it’s time to start the next version, cj68 vII. The other protocol would be to bump the number, but cj69 might lead to smirks.
Stay processing, my friends! Go forth and spread beauty and light.
∇
1 Comment | tags: 3D images, computer generated images, CPU, POV-Ray, programming, software design, sun sign | posted in Computers, Life
 Long distance runners talk about “hitting the wall” — the point where their body runs out of resources, making it almost impossible to continue. I hit an intellectual wall late Monday night. Fortunately, I not only finished the race but went an unexpected extra mile. (And now my brain circuits are fried.)
Long distance runners talk about “hitting the wall” — the point where their body runs out of resources, making it almost impossible to continue. I hit an intellectual wall late Monday night. Fortunately, I not only finished the race but went an unexpected extra mile. (And now my brain circuits are fried.)
Not an actual race (beyond a vague self-imposed deadline), but a hobby project like one of those ships in a bottle. A painstaking and challenging task in the name of fun and exercise of acquired skill. But no race, no ship, no bottle. This was a software project.
My inner geek rampant, I built a virtual 32-bit CPU (in Python).
Continue reading
9 Comments | tags: assembly language, CPU, programming, Python, software design, writing software | posted in Computers, Life
 I’ve been sitting on a fence for several months now, and it’s starting to get a bit uncomfortable. Back in March I opened branch office over in Substack land. Ever since I’ve been trying to figure out whether to shift operations there or remain here. (Or try to do both more or less equally.)
I’ve been sitting on a fence for several months now, and it’s starting to get a bit uncomfortable. Back in March I opened branch office over in Substack land. Ever since I’ve been trying to figure out whether to shift operations there or remain here. (Or try to do both more or less equally.)
A complicating factor is that, despite both Substack and WordPress being blogging platforms, there is something of an apples and pumpkins comparison. They have, for me, contrasting pros and cons, mead and poison.
Change is hard, but it can also be invigorating, and it might just be time.
Continue reading
6 Comments | tags: blog, blogger, blogging, human consciousness, Roger Penrose, Substack, WordPress | posted in Computers, Life, TV Tuesday, Writing

I’m in a post again?
Most online sources define resurfacing firstly as having to do with floors, roads, ice rinks, kitchen counters, and even skin. Only secondarily do they define resurfacing as returning to the surface. But Wiktionary puts that latter one first, and it’s in that sense that I mean it (bravo Wiki!).
It feels as if it’s been a long time since my last post, but in fact it’s been less than a week. It just seems long because it has also been a productive week filled with new things as well as a week of some long hours on a project. Enough hours to have burned me out a bit. Now I have some catching up to do.
But it’s nice to know I can still pull off a coding all-nighter at my age.
Continue reading
9 Comments | tags: Ana Popović, Bentley, Beth Hart, Joe Bonamassa, Larkin Poe, Peter Gabriel, Samantha Fish, Texas Rangers, World Series | posted in Baseball, Computers, Life, Music
 Last post I wrote about a simple substitution cipher Robert J. Sawyer used in his 2012 science fiction political thriller, Triggers. This post I’m writing about a completely different cool thing from a different book by Sawyer, The Terminal Experiment. Published in 1995, it’s one of his earlier novels. It won both a Nebula and a Hugo.
Last post I wrote about a simple substitution cipher Robert J. Sawyer used in his 2012 science fiction political thriller, Triggers. This post I’m writing about a completely different cool thing from a different book by Sawyer, The Terminal Experiment. Published in 1995, it’s one of his earlier novels. It won both a Nebula and a Hugo.
I described the story when I posted about Sawyer, and I’ll let that suffice. As with the previous post, this post isn’t about the plot or theme of the novel. It’s about a single thing mentioned in the book — something that made me think, “Oh! That would be fun to try!”
It’s about a very simple simulation of evolution using random mutations and a “most fit” filter to select a desired final result.
Continue reading
16 Comments | tags: evolution, genetic code | posted in Computers, Wednesday Wow