 Last post I wrote about a simple substitution cipher Robert J. Sawyer used in his 2012 science fiction political thriller, Triggers. This post I’m writing about a completely different cool thing from a different book by Sawyer, The Terminal Experiment. Published in 1995, it’s one of his earlier novels. It won both a Nebula and a Hugo.
Last post I wrote about a simple substitution cipher Robert J. Sawyer used in his 2012 science fiction political thriller, Triggers. This post I’m writing about a completely different cool thing from a different book by Sawyer, The Terminal Experiment. Published in 1995, it’s one of his earlier novels. It won both a Nebula and a Hugo.
I described the story when I posted about Sawyer, and I’ll let that suffice. As with the previous post, this post isn’t about the plot or theme of the novel. It’s about a single thing mentioned in the book — something that made me think, “Oh! That would be fun to try!”
It’s about a very simple simulation of evolution using random mutations and a “most fit” filter to select a desired final result.
The secret code in Triggers turns out to be a Chekhov — something that initially appears trivial and in passing but which later plays an important role in the plot. The string evolution in The Terminal Experiment is genuinely trivial and in passing. It caught my eye because it sounded like it would be fun and interesting to code. (And it was.)
Although it plays no active role in the plot, the explanation of the string evolution idea helps the reader appreciate the fish evolution simulation created by one of the characters. One of the scanned brain AIs central to the story notices the fish simulation and uses it as the basis for a much more sophisticated experiment.
What caught my eye was the idea of evolving strings. As described in the book, it can happen surprisingly quickly, and it sounded like a fun thing to see (and pretty simple to code). True on both counts.
§
To begin: strings. Not the kind that tie packages, get attached, make music, beautify lawns, or are cosmic, super, silly, or cheese. I mean the kind found in computers — strings of characters. They can be any length from zero (an empty string) to whatever the computer allows.[1]
So, a (computer) string is any text from nothing (“”) to as much as allowed in the circumstances (for instance, all the text of this post).
The game of String Evolution starts with a target string (a word, phrase, quote, or whatever) and then uses generations of offspring mutation to evolve a same-length random starting string into the target string.
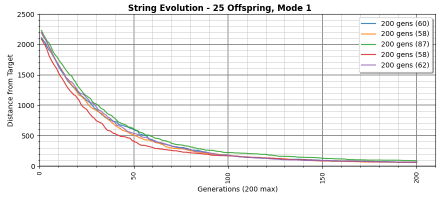
Figure 1. Five runs of evolving a 63-character string. The vertical axis is distance of the current pattern from the target. The horizontal axis is the number of generations (note the long tail). Evolution halted at 200 generations; the legend shows final distance to target in parenthesis.
For example, given the target string ‘The Terminal Experiment, Robert J. Forward, 2012’, a random starting string required only 76 generations to evolve into the target string.
It did it using an effective mutation protocol (which I’ll get to in a minute).

Figure 2. Multiple runs evolving strings of increasing length (horizontal axis). Red plots are number of generations required for an exact match. Blue plots are number of generations to get within 5% of the target. The difference illustrates the long tail. Getting close happens quickly, but an exact match takes much longer.
For now, suffice to say a less effective protocol requires just over 800 generations, best case, and hundreds more, worst case. (All the protocols here eventually do evolve a start string to the target given a few caveats regarding configuration parameters.)
Below is a listing of every other string from the random starting point to the target (the full list would have all 76 strings):
iVdLHY9IAKiAz0GCIvUxVbMGNwptuhjCxTdF6carcHoo9uXi iVdLHY9IAKiAB0GCIvUxVbM9NwptuhjCxTdF6carcHoo9uXi iVdLHY9IAKiABGGCIvUxVbM9NwptuhjCx,dF6carcHoo9uXi iVdLHY9IAKiABGxCIvUxVbM9NwptuhjCI,dF6carcHoo9uXi iVdLHY9IAKiABGxpIvUxVbM9NwptuhjCI,dF6carcHo 9uXi iVdLHY9IiKiiBGxpIvUxVbM9NwptuhjCI,dF6carcHo 9uXi iVdLHY9IiKiiBGxpIvUxVbs9NRptuhjCI,dF6carcHo 9uXi iVdLHY9miKiiBGxpIvUxVbs9NRptuhjCI,dF6carcHo 9u2i iVdLHY9mioiiBGxpIvUxVbs9NRptuhjCI, F6carcHo 9u2i iVdLHY9mioiiBGxpIvUxVbs9NRptuhjCI, F6cwrcH9 9u2i iVdLHY9mioiiBGxpfvUxVbs9NRptuhjCI, F6cwrcc9 9u2i iVdLHY9mioiiBGxpfvUxVbs9NRptuhjCI, Focwrcc9 9u20 iVdLHYqmioiiBGxpfvUxVbs9NRpauhjCI, Focwrcc9 9u20 iVdLHYqmioiiBGxpfvUxVbs9NRpadhjCI, Focwbcc9 9u20 UVdLHYqmioiiBGxpfvUxVbs9NRpadhjCI, Forwbcc9 9u20 UVdLTYqmioiiBGxpfvixVbs9NRpadhjCI, Forwbcc9 9u20 UVdLTYqmioiiBGxpfvixVbs9 RpadhjCI, Forwbrc9 9u20 UidLTYqmioiiBGxpfvixVns9 RpadhjCI, Forwbrc9 9u20 UidATYqmioiiBGxpfvimVns9 RpadhjCI, Forwbrc9 9u20 UidATYqmioaiBGxpfvimVns9 RpadqjCI, Forwbrc9 9u20 UidATYqmioaiBGxpfvimVns9 RpadqtCI, Forwbrc9 2u20 UidATdqmioaiBGxpfvimens9 RpadqtCI, Forwbrc9 2u20 UidATdqmioaiBGxpfrimens9 RpadqtCI, Forwbrc9 2220 UidATdqmioal Gxpfrimens9 RpadqtCI, Forwbrc9 2220 UidATdqmioal Gxpfrimens9 RpaeqtCI, Forwbrc9 2222 UidATdqmioal Dxpfrimens9 Rpaeqt I, Forwbrc9 2222 UidATdqmioal Dxpfrimens9 Rpaeqt I, Forwbrd9 2122 UidATeqmioal Dxperimens9 Rpaeqt I, Forwbrd9 2122 Uid Teqmioal Dxperimens9 Rpaeqt I. Forwbrd9 2122 Uid Teqmioal Dxperimens9 Rpaeqt J. Forwbrd9 2112 Uid Termioal Dxperimens9 Rpaert J. Forwbrd9 2112 Uid Termioal Dxperiment9 Rpbert J. Forwbrd9 2112 Uid Termioal Experiment9 Rpbert J. Forwbrd, 2112 Uid Termioal Experiment, Robert J. Forwbrd, 2112 Tid Termioal Experiment, Robert J. Forward, 2112 Thd Termioal Experiment, Robert J. Forward, 2012 Thd Termioal Experiment, Robert J. Forward, 2012 The Termioal Experiment, Robert J. Forward, 2012 The Terminal Experiment, Robert J. Forward, 2012
It’s surprising how quickly even long strings evolve to their targets. At least initially. The process typically has a long tail. As the current pattern gets closer to the target, progress slows.
Consider the difference between Figure 1, above, and Figure 3, below:

Figure 3. Same 63-character string as Figure 1 but all seven strings evolve until they match the target. The legend shows how many generations it took. The long tail is readily apparent here.
Both show examples of the same evolution configuration, but Figure 1 ended the process at 200 generations (with the strings not fully evolved). In Figure 3 the strings evolved until they reached the target string.
Note how (at least with this mutation mode), a large fraction of progress occurs early, but reaching an exact match takes a huge fraction of the time. That turns out to depend on the mutation “depth”. Progress can be essentially linear if the depth is one (or very low).
§
The basic process is pretty simple. Given some target string as input, generate a string of random characters the same length as the target. Call that the current pattern. We want to evolve it into the target.
Do so with the following loop:
- Use the current pattern to create a new generation of “child” patterns, each with a random mutation. Include a copy of the current pattern as an unmutated offspring.
- Test each child pattern to determine its “distance” from the target. This distance is a numeric value that depends on how different two strings are. A distance of zero indicates the strings match exactly.
- From among the children, pick the child with the lowest distance value (the one most similar to the target string). Note that if all the mutations are more distant then their parent, the unmutated offspring is closest and is selected (and no change occurs that generation).
- If a child has zero distance from the target, it’s a match, and we’re done. Otherwise repeat the loop with the selected child as the new current pattern.
We can parameterize the loop in several ways. A crucial one is how we mutate the pattern string into a new string. Another is how many children occur each generation. We should also have a max-generations setting in case the loop never matches the target and wants to go forever!
§
In String Evolution, mutating a string of characters involves altering one or more of the characters in a string.
The first mutation parameter is how many characters to alter. I was surprised to find that having more than one mutation per offspring actually reduces evolutionary progress. Upon reflection, it’s apparent why. Multiple mutations make a string jump a larger distance. A pattern selected as the closest can produce offspring that are more distant to the target than the parent. In some cases, the search can dither, jumping closer and farther, back and forth, running forever.
Bottom line, a single mutation per string works best by far.

Figure 4. Same 63-character string as used above, but evolved using mutation mode 2, which forces the mutation depth to 1. This results in a linear evolution with almost no tail.
The more critical mutation parameter is the mutation depth. This controls how much the character being changed can change. With a depth of 1, the character can only change to the previous or next character. For instance, an ‘S’ can only change to an ‘R’ (-1) or a ‘T’ (+1). On the other hand, if the mutation depth is 5, an ‘S’ can change to any of: ‘N’, ‘O’, ‘P’, ‘Q’, ‘R’, ‘T’, ‘U’, ‘V’, ‘W’, ‘X’ (-5 to +5, respectively).
Alternately, the character may change to any other legal character. (As if the depth was infinite.)
In my code, this led to three distinct mutation modes: (1) Random character; (2) Depth forced to ±1; (3) Depth specified by depth parameter.
As illustrated in Figure 4, mutation mode 2 results in linear evolution. (Because the pattern can only evolve per a ±1 change to a single character.)

Figure 5. Similar to Figure 2 but using mutation mode 2 (linear evolution). Note how the blue “5% left” lines no longer indicate a process with a long tail. They are, on average, 5% short of the matching red line.
Mutation mode 3 offers a spectrum between mode 2 (if depth=1) and mode 1 (if depth is set to a large value). The former makes mode 3 exactly like mode 2. The latter differs in that mode 1 assumes a flat distribution — the changed character can be any character with equal probability. Mode 3 with a large depth setting implies a distribution centered on the original character. (That distribution can even be biased rather than flat.)
Figure 6 below shows the effect of the mode 3 mutation depth parameter:

Figure 6. The effect of the mutation mode 3 depth setting on the number of generations required to reach the target (the same 63-character string as used in the charts above). The depth varies from 1 to 150 across the chart.
Note the poor performance at depth=1. It’s what we’d expect to see for mode 2, around 2500 generations. This drops rapidly to a sweet spot from around 7 to 15 or so (only 500 generations) and then begins to rise. How high turns out to depend on how the offspring setting.
I believe the “cliff” just before 100 is from alphabet wraparound during mutation.
§
One obvious parameter is how many offspring occur each generation. So long as enough offspring occur (which depends on target length), the pattern evolves towards the target. Depending on the mutation mode, the offspring setting can sometimes improve (or diminish) evolution progress.
The size of the target string obviously has a strong effect on how long it takes (how many generations it takes) for the pattern to evolve to the target. Figure 2 and Figure 5 show how target string size correlates with how many generations it takes to match the target. Figure 7 below shows something similar:

Figure 7. Evolution curves for different length strings. In the legend, [###] is string length. The “max” label means the evolution “maxed out” (didn’t reach the target in 600 generations). The (###) indicates the pattern’s distance from the target with the process was stopped. See how the 30-character string got within one character!
Note that mutation mode 2 is generally slower than the 1 and 3 modes.
Combined with varying the offspring size, the mode 3 depth setting allows tweaking for very good performance. Even so, mode 1 is generally competitive.
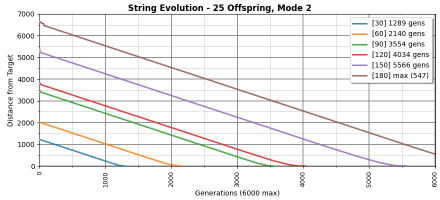
Figure 8. Same as Figure 6 but using mode 2. The curves start at roughly the same place (their respective initial random strings), but they take much longer to reach their targets.
But in Figure 8 note how the same six string segments take about ten times as long using mode 2 linear evolution.
§ §
One thing about the way this works is that each generation produces a set of children, each of them mutated. A copy of the parent is included as an unmutated child.
In nature, most offspring are not mutated, and progress is much slower. It can involve millions or billions of generations. Using a group of mutated children (each with a separate mutation) massively speeds things up. Selecting the offspring with the best score (closest pattern) and discarding the rest amplifies and distills the progress.
Therefore, it’s not so surprising we can evolve from:
qcO+RhiPO3`ZT@e:oOoR:oLnKM:;K=_h=J84^xjTp~pGD~<uV`2- ;P1″zhw}|w”ige7WldTC)ctAgzo3,Dj!s@UvNxXSc\[)7VUpdTMP\^0HK5;r}&Moyu-JV0+t_Wu[rJH!5@xn0QE+e7c=I[pX{)i~OXp”&4?B84yXIH}b]n6|wjhZWH\3
To the well-known Frank Zappa quote:
You can’t be a real country unless you have a beer and an airline. It helps if you have some kind of a football team, or some nuclear weapons, but at the very least you need a beer.
In only 1178 generations (mode 3, depth 15, offspring per generation: 50). The original random string had a distance of 6303 from the target string.
§ §
I’ve had a lot of fun exploring this and poking around in how it all works. For those interested, I expect to post the code on my computer programming blog. RSN
Stay evolving, my friends! Go forth and spread beauty and light.
∇
[1] A string with a single character is sometimes referred to as just a character. In some programming languages there is no difference, but in others a one-character string and a character are different data types. In such cases, generally the string can have zero, one, or many characters, whereas the character always has the value of some single character (it’s never zero or many).












June 15th, 2022 at 11:11 am
This is fascinating and fun to think about! I love Frank Zappos’s definition of a country. That’s a great fit for my political science class slideshow on the nature of the state.😂
June 15th, 2022 at 11:33 am
Yeah, I’ve had a ball the last few days playing around with it. It’s really fun watching a string of gibberish slowly turn into a known quote. Almost seems like a kind of magic. And kinda weird how different tweaks have a big impact on how many generations it takes (like mode 2 being roughly ten times slower).
That Zappa quote is a favorite. Another of his I really like is the one about how human stupidity is a more common element than hydrogen.
June 15th, 2022 at 12:37 pm
I meant to mention: That 63-character string featured in a lot of the graphs is, “Some subjects are so serious that one can only joke about them.” It’s due to Niels Bohr and is one of my favorite quotes of all time.
June 15th, 2022 at 12:41 pm
While I’m on the topic of favorite quotes, another is “I cannot remember the books I’ve read any more than the meals I have eaten; even so, they have made me.” That one is due to Ralph Waldo (Emerson), and I think it’s a striking insight about both books and meals. It especially resonates with my life-long inability to remember the details of books and movies while still retaining what I learned from them. (It’s almost like I discard the chaff to make room for more wheat.)
June 15th, 2022 at 12:44 pm
When I needed a fairly short string, I used the 43-character “It takes a long time to understand nothing.” At least one of those infamous Ancient Greeks expressed the sentiment, but the words here are due to Edward Dahlberg.
June 18th, 2022 at 11:06 am
I wrote a genetic Trading Strategy breeder.
Could consume any number of “indicators”, treatments (RSI, MACD, Bollinger) of inputs (price, volume, fundamentals) — with the genes being the configuration of said indicators — that drove the health of the individual strategy. The health of course being manifold: low variance, high profit, low drawdown.
Worked slick. But of course, this is just classic curve fitting. Tune it perfectly, produce the healthiest individual (or diverse configuration family) and paper trade it (them, basket-trading).
Without fail, it would fail. The markets are non-rational and do not follow historical patterns reliably. WHAM Covid. WHAM Lehman Bros.. WHAM oil crisis. WHAM, WHAM, WHAM.
But, boy do I remember the excitement of watching the breeding engine go to town.
June 18th, 2022 at 3:07 pm
It’s a lot of fun! And I was thinking about how you could evolve anything you could parameterize. I’ve been trying to think of something fun to evolve other than text. It was virtual fish in the novel. Virtual critters would be interesting, but I want something fun to animate.
(Which reminds me; I want to do more and better 3D Life. I’m currently back to playing around with particle animation now that I found the right algorithm for momentum transfer during collisions. I was just swapping momentums between colliding particles. That works for direct collisions, but not glancing ones.)
Was your algorithm linear or did it have a long tail? I can imagine the market is beyond chaotic; I would guess it’s noisy AF and constantly evolving. Hard to learn a system like that. Possibly impossible.
June 18th, 2022 at 3:16 pm
Well, the distribution was Pearson and evolved to standard, But that was just plotting the metrics we used. And of course we didn’t pay attention to Taleb’s leptokeurtosis. Which, is exactly why forward testing would kill the golden ones (made actually of lead).
More a coffin nail is the rise and fall of a site call Quantopian.com. It touted, in the end, trying to democratize the ML of quantitative trading. BOOM and DIE. I participated early on but became disenchanted as the reality of market behavior (or misbehavior) became glaringly evident.
June 18th, 2022 at 3:37 pm
Yeah,… all I know about the market is that I have no business being anywhere near it! 😨
Evolving a 3D shape might be interesting. I’ve seen some examples.
June 18th, 2022 at 3:18 pm
Just for grins (also for shits ‘n’ giggles), I ran the first paragraph of the post through the evolution process. It has 336 text characters.
Mode 1: 4,076 generations
Mode 2: 12,403 generations
Mode 3 (depth=15): 2,866 generations
Each generation had 50 offspring in all three cases. The random string, different in each case, had a distance from the target text of about 12,000. Mode 3 leverages that sweet spot, but Mode 1 sometimes still beats it. As Figure 2 shows, there is a lot of variation in how many generations it takes.
June 18th, 2022 at 3:25 pm
Below is the current pattern string halfway through the Mode 1 evolution (generation 2,033). It has a distance from the target of only 38 (from a starting distance of 11,442). It’ll take just over 2000 more generations for it to close that distance to zero.
Last!pnst I wrote!about!a!simple svcstitutioo ciqher Qpbert J. Sawyer!used in his 2012!science fictioo political thrilleq, Triggfrs. Shis post I'm writing about a completely diffeqeos cool!thing from b digferent book by Sawyer, The Terlinal Experiment. Puclithdc in 1995, jt's one of his farlier!novdms. It woo both!a Necula anc a Htgo.June 18th, 2022 at 3:30 pm
The Mode 2 linear evolution makes the halfway point string a mess of gibberish and not worth showing. The Mode 3 halfway point string looks similar to the Mode 1 one. This one happens to have a distance of only 30 (and after only 1433 generations), so while the long tail is still present, the overall time is less. (At least in this run.)
Last posu I wrote!`cout a simple substitution cipher Robert I. Sawyer used in!his 3012 science ficuion pomitical thriller, Triggers. Thit qost H'n!writing abouu ` cnmpletely dieffrent cool thing!fsom a djfferenu book by Sawyer, The Terminal Experiment/ Published!jm!1995, it's one of his earlier novels. It xon both a Nebula and!a Hugo.August 20th, 2022 at 4:32 pm
[…] bias on my part. I’ve posted about him (twice) recently. Ideas in his books account for two other posts. I can’t say every book is a home run, but they are all at least extra base hits for […]
November 9th, 2022 at 2:17 am
I never got around to posting the code on my other website. (Not that anyone’s asked after it.) Note to self: post the code!
November 10th, 2022 at 8:44 pm
On the other hand, this post only ever got 14 hits. Obviously, no one is interested, so meh. The main Python file is 48K, so it’s a lot to try to write about.
March 21st, 2025 at 12:56 pm
[…] Again, the situation of potential growth without limit in the context of finite resources. This experiment provided bits of code and some sort of rules by which they could combine. Given such a system, especially if something acts as a selective force, it can be surprising how quickly it evolves to a complex end state. [For an example, see String Evolution.] […]