 Last time I set the stage, the mathematical location for quantum mechanics, a complex vector space (Hilbert space) where the vectors represent quantum states. (A wave-function defines where the vector is in the space, but that’s a future topic.)
Last time I set the stage, the mathematical location for quantum mechanics, a complex vector space (Hilbert space) where the vectors represent quantum states. (A wave-function defines where the vector is in the space, but that’s a future topic.)
The next mile marker in the journey is the idea of a transformation of that space using operators. The topic is big enough to take two posts to cover in reasonable detail.
This first post introduces the idea of (linear) transformations.
I mentioned in the Introduction that, despite the unfamiliar name, linear transformations — using linear algebra — are just a cool kind of geometry.
As with many forms of geometry, linear algebra generalizes to any number of dimensions, but (as with many forms of geometry) we’ll explore it in two dimensions to build the necessary intuitions.
So we will assume a 2D Euclidean space that we’ll view as vector space. (See previous post for details.)
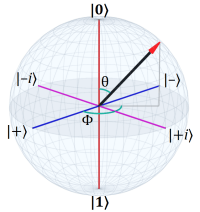
Every point in the space has an associated arrow (a vector) with its tail at the origin and its tip at the point. These vectors give each point a magnitude, eta (η), and an angle, theta (θ).
Additionally, we multiply the Y-axis by the imaginary unit, i, to create the 2D complex plane. This lets us leverage the following identities:
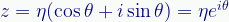
The third form, the exponential, is especially helpful in wave mechanics in general and in quantum mechanics in particular. We’ll explore that in more detail in future posts. For now we start simply…
§ §
A transformation in this space is a function (or something we treat as one) that takes a vector from the space and returns a new vector. We say a transformation maps vectors to new positions in the space.
The simplest transformation is to do nothing at all. For now, we’ll call this the Null transformation. It maps all vectors onto themselves. (Think of it as multiplying by one.) We’ll use notation that looks like this:
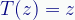
This defines transformation T, which takes complex number z as input. In this case the transformation is defined as simply the input vector, z.
Figure 1. The space before (left) and after (right) the Null transform.
A transform map need not be bijective; it can be non-injective and/or non-surjective. The domain (the input) is all vectors, but the codomain (the output) need not be complete or unique.
Put less mathematically, the map takes every vector in the space as input, but it’s allowed to map different vectors to a single output vector. It’s also allowed to leave “voids” in the output — vectors no input will map to.
§
Here’s a transformation (we’ll call it Real) that converts all vectors to real numbers by taking their real value (and ignoring their imaginary value):
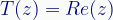
Where T(z) is defined as the function Re(z), which is a standard function that takes a complex number and returns the real part. (Its counterpart is Im(z), which returns the imaginary part. Note that both functions return real numbers.)
Figure 2. The space before and after the Real transform.
The result of the transformation is the one-dimensional real number line; the 2D complex plane collapses to a 1D line. All vectors “lie down” on the X-axis.
This, as mentioned, leaves the 2D space unmapped, and many vectors from that space end up mapped to the same vector.
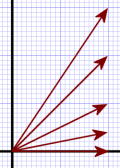
Figure 2a.
Notice that the vectors already aligned with the X-axis don’t move. This fact, that some vectors don’t move under some transformation, becomes hugely important later under the heading of eigenvectors.
In Figure 2a (which is before transform), all five vectors shown, after transformation, end up as the bottom vector that’s already lying directly on the X-axis. They all map to the same result vector.
That bottom vector doesn’t change and ends up as itself. Therefore, that bottom vector is an eigenvector of the Real transformation because it doesn’t change under that transformation. (There’s a bit more to it than that, but that’ll do for now. I have post coming later about eigenvectors and eigenvalues.)
§
We can also imagine a transformation (call it Zero) that collapses all vectors to the zero vector:
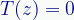
This (rather useless operation) reduces the entire space to a zero-D space — a single point.
Figure 3. The space before and after the Zero transform.
(Normally, transformations are not quite so reductive. These trivial examples serve to illustrate the notation and introduce the basic idea of a transform.)
§ §
In linear algebra, there are two important rules with regard to the allowed types of transformation:
• Firstly, the origin must remain in place; it never transforms. The zero vector remains the zero vector under transformation.
• Secondly, the transform must be linear, meaning it must preserve straight lines. Note that grid lines do not have to remain orthogonal (at right angles) or in any particular orientation — just straight.
§ §
The Null, Real, and Zero, transformation all obey these rules. The Real transformation collapses the vertical axis, and the Zero transform collapses both, but, they remain straight in the limit.
Speaking of which, if we think of the Zero transform as taking place over time, we see the vectors all shrink proportionally until they’re all zero. During this, the origin remains centered, and the axes remain straight. This implies another kind of transformation, Scale, that shrinks or expands all vectors proportionally by a factor:

The transform takes a scaling factor, sf, that determines how much to shrink (sf < 1.0) or expand (sf > 1.0) the vectors.
Figure 4. The space before and after a Scale(0.5) transform.
Note that, in reality, the “after” image should be covered with a half-sized grid, but in these examples I only transform the visible part of the “before” space to help illustrate the transform. Just remember that the transform includes the entire space.
§
Another legitimate transformation is a rotation, call it Rotate, that takes an angle, θ (theta), that specifies how much to rotate the space.
Rotate is always around the origin, which preserves the origin, and rotation also preserves straight lines.
Figure 5. The space before and after a Rotate(30) transform.
(Again, I’m only transforming the visible part of the “before” space. In reality the entire space is transformed.)
A rotation transform can include a scale transform, so:
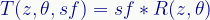
Transform T takes a complex number, z, an angle, θ, and a scaling factor, sf. The definition assumes another transform, R, that takes the number and the angle and does the rotation transform. The resulting vector is then scaled by sf.
Figure 6. The space before and after a RotateScale(30, 0.5) transform.
As we’ll explore in the next post, there are various ways to accomplish these transforms, but all of them can be represented by square matrices (which is how I’ve done all the images you see here). To give you a taste of what such a matrix looks like, here’s the matrix for the RotateScale transform:
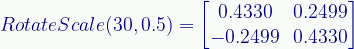
I won’t, in this series, explain exactly how this works because I’ve already covered that ground. See the Matrix Rotation and Matrix Magic posts.
§
We’ve seen transforms collapse axes, scale, or rotate (or do nothing). There are two additional transforms that preserve the straightness of axes.
First, note that above we had one transform that scaled the whole space, and another that collapsed one axis. The collapse is actually a scaling of that axis to zero. We can also scale one axis to some scaling factor:
Figure 7a. The space before and after a ScaleY(0.25) transform.
We can shrink or expand along any axis. The above scales the Y-axis, the below the X-axis:
Figure 7b. The space before and after a ScaleX(0.25) transform.
We can also scale on a diagonal:
Figure 8. The space before and after a Lorentz(0.5) transform.
In fact, this is the same transformation we see under a Lorentz transformation — the transformation we see of a frame moving relative to us. The example above represents the frame shift due to moving at 0.5 c.
§
The last transformation I’ll show you is a shear:
Figure 9. The space before and after a Shear(M) transform.
Note that, unlike the Lorentz transform, which rotates both axes, a shear only rotates one axis (in this case the Y-axis). The other axis just “slides” (or shears, hence the name).
It may not mean much right now, but the last two transforms (as far as I know) are pretty strictly matrix transforms. That’s why Shear(M) takes a matrix — it’s the only way to easily specify the transform.
To repeat an important point, a linear transformation preserves the straightness of the axes, but (as in the last two cases) need not preserve angles. The prior transforms all maintained the 90° orientation of the axes, but the last two obviously don’t.
§ §
The main point is that a transformation implicitly applies to all vectors in the space. The red grid in the examples stands in for all the vectors in the space.
In fact, we can use transforms to smoothly transform a continuous space:
Figure Bender (no one can). Before and after a shear transform.
Note that I arranged to have the pixels that were shifted off to the left be wrapped around to the right so we can see them — that is not part of the transform. To show it properly would require enlarging the after space to the left.
§ §
That’s enough for this time. Next time we’ll get into these transforms as operators on the space and talk about how they’re implemented.
I highly recommend, in general, Grant Sanderson’s ThreeBlueOneBrown YouTube channel for learning about mathematics in a fun visual way. It’s one of the best math channels around.
In particular I recommend his Linear Algebra playlist which introduces linear algebra in fairly short videos with outstanding animations and explanations. I’m deeply indebted to the channel and this series for helping me understand this stuff at a much deeper, more fundamental, level.
There are many other free resources available. Even Wikipedia has a lot, although it’s not always the best resource for beginners. It is pretty great once one gets rolling, though.
Stay transformed, my friends! Go forth and spread beauty and light.
∇













February 15th, 2021 at 8:43 am
Something that might be getting down in the weeds, but which thoughtful readers might wonder about…
Generally speaking, there is a two-step process in a transformation. The first step is the definition, the second step is the application. I’ve compressed both steps into the application step for simplicity.
The first transforms, Null, Real, Zero, etc, just took a parameter, the complex vector to be transformed:
Which is how all transforms would normally work — they just take the input vector and return some new vector.
But I showed some transforms, Scale, for example, as also taking a scaling factor parameter.
Which combines the parameter for the definition with the parameter for the application. The reality would look more like this:
Where Scale(sf) is a definition function that returns a transform function that scales using the supplied sf parameter and an expected x parameter to be supplied later. The application of that transform then actually works like this:
So the transform just takes a complex vector, z. The transform already knows the scaling factor.
Which, I realize, may be a little confusing unless one has some programming background, because we’re talking about a (definition) function that returns a (transform) function. As such, the first (def) function is returning something that is, in a sense, “incomplete” until it’s used and the expected parameter is supplied.
Clear as mud? You can see why I avoided it in the post! 😉
February 15th, 2021 at 9:04 am
I’ll mention again that I’m laying a foundation for future posts, and this stuff is very foundational, so be sure it’s all as clear as possible. I encourage serious readers to ask questions about any point that’s unclear, because if stuff is unclear now,… well, it’s just gonna get worse down the road.
February 16th, 2021 at 10:10 am
This one got pretty mathy, which made it tough for me to stay focused, even after going through it twice (once last night and once this morning). I might have to come back to it after it becomes obvious later what part of the physics requires it.
February 16th, 2021 at 1:47 pm
This is a math journey, so getting mathy doesn’t just go with the territory, it is the territory.
Truth is, this post has very little math compared to where we’re headed, so if the water seems deep here, it’s only going to get deeper. Unfortunately it’s the only way to get past the language-based accounts of QM.
As I mentioned before, this is the time to ask questions and build foundation knowledge. Would it work to read it again with a pen and paper to note anything that isn’t clear and then ask about it?
But if the math is making your eyes glaze, I’m not sure what to do about that. Lots of coffee? 🙂
I think there is a commitment that needs to be made if one wants to get into this stuff. It might be a bit like deciding to start going to the gym regularly or sign up for school courses. All I can do is point the way, offer to help, and try to provide tips for the harder stuff.
(I don’t know to what extent various old posts of mine might help. A lot of what I’m writing now does refer back to some of that material.)
February 16th, 2021 at 2:39 pm
It might be a commitment I’m just not up for right now. I’ll just continue skimming the posts. It’s possible when I see what I’m not grasping about the physics, I’ll be motivated to come back and hit the straight math again.
Sorry, just my hang up. Pure math has just never done it for me.
February 16th, 2021 at 4:26 pm
It’s definitely a big commitment! It would require a fair amount of work with the only payoff being the ability to see deeper into QM. (I will say, speaking for myself, it was and continues to be worth it. I’m liking the view a lot, but I’ve always been a bit of a math head.)
I don’t know if this would help, but maybe framing it not as “pure math” but as foundation knowledge and the prerequisite for QM and deeper physics in general. Kinda like learning to read isn’t “pure reading” so much as building a skill? (The gym analogy, come to think of it, is fairly apt.)
February 16th, 2021 at 5:54 pm
FWIW: I believe you’re roughly 10 years younger than me, so roughly in my age range. One reason I actively explore new topics — areas where I have a lot to learn — is explicitly to try to keep my mind from senility or even hardening. That was part of why I got into baseball, and it’s very much a part of why I’m tackling math in my old age.
It has certainly not escaped my attention that, among older family members from grandparents on down, it was the intellectual types who pursued their interests until, literally, the day they died, who had the sharpest minds until the day they died. My dad’s dad, hugely mentally active, writing essays and doing research, died at 91 because he slipped on the ice opening the garage door, got a broken hip, and that eventually brought him down.
Some of it is no doubt genetic, but “use it or lose it” still does apply.
So for me there’s a double goal: learning more about QM at the “real” level and not going senile!
February 16th, 2021 at 6:53 pm
I agree completely on keeping mentally active. But there are many different ways to do that. If learning the mathematics of QM works for you, awesome! I’ll never be more than a dabbler myself, with it just being part of a more diverse set of interests.
My approach on the mental agility front is to keep challenging myself with new concepts, particularly anything that shakes my preconceptions. A lot of my older relatives display a type of rigidity that I really want to avoid.
February 16th, 2021 at 7:06 pm
Oh, totally and mos def! Whatever, as they say, floats your boat!
February 16th, 2021 at 9:11 pm
I’ve been seeing interesting articles about researchers using a quantum computer to simulate non-Hermitian quantum mechanics:
“The first discovery was that applying operations to the qubits did not conserve quantum information — a behavior so fundamental to standard quantum theory that it results in currently unsolved problems like Stephen Hawking’s Black Hole Information paradox.”
Now, that is interesting!
https://scitechdaily.com/new-physics-rules-tested-by-using-a-quantum-computer-to-create-a-toy-universe/
February 16th, 2021 at 9:13 pm
I’ve long been suspicious of the idea that quantum systems conserve information. Unlike conservation of energy or other physical properties, there doesn’t seem to be an associated symmetry underlying the notion of conservation of information. It’s been more an assertion of QM based on the use of unitary operators.
I’ve never fully accepted that it’s a required truth, and these results suggest it might not be.
February 22nd, 2021 at 7:48 am
[…] — where we see every point in the space as the tip of an arrow that has its tail at the origin. To that we added the notion of (linear) transformations that change (map) all the vectors to new vectors in the […]
March 1st, 2021 at 7:48 am
[…] previous posts about operators and transforms for more on this and the following […]