 Last time we looked at the basic requirements for a software model of a computer and put a rough estimate on the size of such a model (about 2.5 terabytes). This time we’ll consider a software model of a human brain. Admittedly, there’s much we don’t know, and probably need for a decent model, but we can make some rough guesses as a reference point.
Last time we looked at the basic requirements for a software model of a computer and put a rough estimate on the size of such a model (about 2.5 terabytes). This time we’ll consider a software model of a human brain. Admittedly, there’s much we don’t know, and probably need for a decent model, but we can make some rough guesses as a reference point.
We’ll start with a few basic facts — number of neurons, number of synapses — and try to figure out some minimal requirements. The architecture of a viable software brain model is likely to be much more complicated. This is just a sketch, a Tinkertoy® or LEGO® version.
Even so, we’re gonna need a lot of memory!
We start with three numbers related to the human brain:
- Number of neurons — 100 billion.
- Average number of synapses per neuron — 7000.
- Total number of synapses — from 100–1,000 trillion.
The second and third numbers imply each other. The neuron synapse average is important to our neuron design. The synapse total turns out to be the main factor in how big the model is.

This is what we’re trying to model.
How big is it?
Before I get to that I want to stress that this is a model of a static brain — a quiescent brain thinking no thoughts, not even autonomic ones. A model of brain function (let alone consciousness) requires much more than this.
This is, at best, the canvas, not the painting.
I also want to point out something striking. The size of the software model of a computer was dominated by the table of stored memory states (2+ terabytes). The software stored on the system accounts for most of the information content. The model’s table of interconnections was much smaller (48 gigabytes, maybe as high as 480).

A vast network!
In a model of the human brain, the interconnection table (including the synapse description) is pretty much the entire model. And it’s big!¹
Okay, so how big is the model?
We’ll assume a 64-bit computing world. We’re pretty much there now, and 64 bits is big enough (counts up to 18 quintillion) that it may survive a few generations of computing.²
Given about 100 billion neurons (10¹¹), assuming a 64-bit word for each neuron state means 800 gigabytes for a whole brain.³ For just a snapshot of the neuron states at some instant.
In one sense, neurons have only two states — firing or not firing — but there are different types of neurons (which needs to be modeled), and I suspect even their static states are more complicated than firing or not firing.
Crucially, when neurons fire they fire trains of on-off pulses, and the timing of those pulses carries significant information. The strength of a pulse can’t vary, but the frequency can. At the very least a ‘neuron firing’ state needs to encode the pulse timing.
The point is, unlike a transistor in a computer with just an on or off state, a single bit won’t suffice for a neuron.
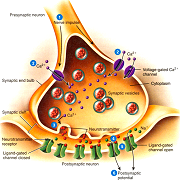
A complex mini-machine!
Whether 64 bits is overkill or insufficient, I do not know. As it turns out, the synapse requirements seriously overwhelm the neuron requirements, so this one hardly matters.
We can double or quadruple the 800 gigabytes with very little impact to the total model size.⁴
What dominates is the 100 to 1,000 trillion synapses (10¹⁴ to 10¹⁵). We want a high-end brain, so we’re using the full-size one quadrillion synapse count.
As with modeling the neuron, modeling the actual synapse is just a bunch of bits describing the type and state of the object. I’ll assume 64 in this case, too (but synapses are very complicated and 64 might not be nearly enough).
Note that, in the same way we can model the behavior of all transistors in the computer with one model, we can leverage similar states among neurons or synapses to reduce model size.
Let’s imagine there is some node (neuron or synapse) state that takes thousands of bits to fully describe for our model. Billions of nodes share the ability to have that state, so a brute force model has to replicate those thousands of state bits billions of times.
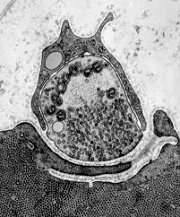
A real synapse!
But if that complex state is put in a table of complex states, nodes can use a small number as an index into the table. That allows us to cut down on how many bits it takes to model a neuron or — especially — a synapse.
The thing about synapses is that they appear to be extremely complicated. (I’ve read one neuroscientist refer to them as the most complicated biological machine we know.) It’s very possible 64 bits is nowhere near enough to model a synapse, even with table lookup.
For example, our memories are stored in the Long-Term Potential (LTP) of synapses. The hugely interconnected brain and the (changing) strengths of those connections is what comprises a person. In a sense, the operating system software is built into the structure of the hardware.
As such, our 64-bits per synapse guesstimate is likely bare minimum.
§
So how do we model that vast network of synapse connectivity?
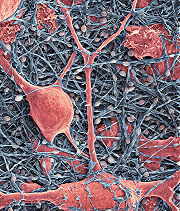
Neurons (pink) amid a matrix of glial cells.
There are many ways to model a network, but they all have a common requirement (one that directly concerns us): describing a link requires naming the nodes it connects to.
This means we need space for two sets of names: source nodes and destination nodes.⁵
As with the transistor network in the model of a computer, we describe the connection from ‘A’ to ‘B’ and the reverse connection from ‘B’ to ‘A’ (which does mean each connection is described twice).
So we’ll model neurons as complex objects that each contain both axons and dendrites (the source and destination lists). Each neuron will have:
- A state
- An axon-synapse list (of neurons it connects to)
- A dendrite-synapse list (of neurons connecting to it)
- A synapse state list
Now we can determine how big our model is. Addresses in the model need to handle the size of the model. That takes about 50 bits⁶, so our address links easily fit in 64-bit words.
We’ll have some bits left over, and those might be used for marking or for some other link property. Synapses can be located different places on the neuron — perhaps describing that is a use for those extra bits.
We saw that the neuron state data set is 800 gigabytes. Each synapse has an axon link and a dendrite link, both 64-bits. That’s (are you ready?) 16 petabytes⁷ just for the connection model. The synapse state data set is another 8 petabytes (assuming one 64-bit word suffices.)
§
 All told, our Tinkertoy brain model weighs in at 24 petabytes! (Plus 800 gigabytes for the neurons — a drop in the bucket at this point. Now we see why the size of the neuron model isn’t significant.)
All told, our Tinkertoy brain model weighs in at 24 petabytes! (Plus 800 gigabytes for the neurons — a drop in the bucket at this point. Now we see why the size of the neuron model isn’t significant.)
Compare that to the 2.5 terabytes of the computer model. Our static brain model is four orders of magnitude (ten-thousand times) larger than our static computer model!
There is also that the operational software model of the computer is very simple given the static model. The operational model of the brain is likely to also be many orders of magnitude more complicated. For one thing, there is a huge degree of parallelism in the operation of the brain.
§
Something else to consider: At a rate of 1 terabyte per second, it takes over 16 minutes (16:40) to transfer 1 petabyte. Which means it takes over seven hours (7:46:40) to transfer 28 petabytes. Something to think about when it comes to uploading or downloading.⁸

CERN data center
One thing we can see is that, in the context of current hardware, building a software brain model is resource intensive.
I keep thinking about the massive machinery and data-handling at CERN — so much data they have to discard the less interesting — all in service of studying a domain much smaller and faster than an atom.
Might our early efforts require such giant science centers? Large server rooms filled with hard drives and parallel processors (and all the support machinery that requires)?
All so we can sit down at an interface and say, “Hello, HAL! How are you feeling today?”
§
 Finally, we can consider the size of a snapshot of the brain, which would be the state of each synapse (and possibly the state of each neuron if that cannot be derived from the state of a neuron’s synapses).
Finally, we can consider the size of a snapshot of the brain, which would be the state of each synapse (and possibly the state of each neuron if that cannot be derived from the state of a neuron’s synapses).
Synapse state is complicated, remember. Our bare-bones estimate was 64 bits (8 bytes). A synapse snapshot is that eight petabytes of synapse state (along with, maybe, the 800 gigabytes of neuron state).
An ordered list of synapse states is 8 PB compared to the hundreds of megabytes of an ordered list of transistor states. An unordered list adds the requirement of synapse labels, which adds another 8 PB (essentially, half the double-link connection map).
So any given instant in a brain is (unsurprisingly) vastly more complex than any given instant inside a computer. (Which is why no computer system we have now is anything like a brain, even when you factor in software.)
Last time I left you with what seemed like a big number: the total number of different states (snapshots) a computer can generate. I said seemed because here’s the configuration space (total possible states) of the human brain:
One problem here is that we don’t know what S above should be. It’s the number of possible states a synapse can have. It’s definitely more than two (like a transistor), but how much more is unknown (at least to me). Would 256 be enough? 1024? More?
We assumed 64 bits for synapse state, but some of that is used by the LTP and other characterizations of synapse type and operation. The actual synapse state at any moment (given the synapse properties) might take much less to specify. As a complete WAG, let’s suppose 16 bits (65,536 state levels).
That means:
Or:
Compare that to the computer configuration space from last time:
Rather a bit bigger! (And that’s assuming only 16 bits describes a neuron state! The odds are a much bigger number is more correct.)
[1] The human brain is a highly interconnected physical network. Each of those 100 billion neurons has, on average, 7000 connections. The total synapse count varies from 100 to 1,000 trillion depending on age and other factors. We’ll use the high end, 10¹⁵ (one quadrillion aka one peta-).
[2] You never know, but I’d still bet memory and CPU sizes expand many times before a 64-bit data bus does. You can reach a point where all those bus wires become unwieldy at connection points.
[3] It takes eight bytes to contain 64 bits, so 100 billion neurons × 8 bytes = 800 gigabytes.
[4] A similar question occurs with the synapse model, and there it has much more impact on the model’s total size.
[5] It’s possible to create a directed network of one-way links and that eliminates the source node list. But tracing a path backwards through the network becomes computation intensive. You can only find previous nodes by searching the entire network for nodes that link to the current node.
[6] With 50 bits we can address 1015 table locations. Just what we need. (If we use actual memory locations we’ll need more bits, but even so 64 is enough.)
[7] The math: 10¹⁵ synapses × 8 bytes (64 bits) per synapse × 2 table entries (axon and dendrite) = 16 petabytes (16×10¹⁵ bytes).
Just consider one petabyte. You know those 2 terabyte (2,000 gigabyte) drives? Five hundred of those. (Or one-million one gigabyte drives!)
To give you an idea: Western Digital makes a 2 TB drive (WD20EARX) that measures 1″ high × 4″ wide × 6″ long. Stacking 500 such drives makes a 4″ × 6″ tower over 41 feet tall. For one petabyte!
[8] At a more current speed of 100 gigabytes (bytes, not bits), it would take ten times as long!














October 30th, 2015 at 8:21 pm
how powerful the ability of the human brain, let alone create it
October 30th, 2015 at 8:46 pm
Powerful enough, perhaps, to re-create itself!
October 31st, 2015 at 1:34 pm
Speculating on how brain structures might map to computing is always an interesting exercise.
There are some things that might mitigate the model size. You used a high end synapse count estimate, but most of what I’ve read puts it closer to 100-150 trillion. I also suspect that the link address sizes could be mitigated by the way neurons are clustered, possibly allowing a more relative addressing in many cases. Even if we stick with a neuron global address space, I only count 40 necessary bits (5 bytes), which could bring the size down. (Although perhaps with a performance hit on a 64 bit system.) And, despite their complexity, the effect of the synapse on the network might come down to its strength (possibly only 8-16 bits), whether it is inhibitory or excitatory (a bit), and what effect a signal going over it has on its strength.
On the other hand, we’d probably also have to model the topology of the axons and dendrites. How far is the synapse from the pre and post synaptic nucleases? (Could be microns or several feet.) How much has the axon or dendrite branched before the synapse? Are there other synapses between these same two neurons? These would alter the signal that eventually makes it to the post-synaptic nucleus, not to mention the timing.
And we’d almost certainly have to model glial cells, particularly astrocytes. They may or may not participate directly in cognition, but their capacities and constraints almost certainly have an indirect effect on what happens.
Accounting for neuron topologies and glial cells (and their topologies as well) might drive up the model size even higher.
All of this is why I’ve said on other threads that I’m uneasy that this is the path that mind uploading would ultimately take. The amount of computing resources necessary may never be readily available. Moore’s Law would have to continue unabated for several more decades, and there are indications that it’s already slowing down.
Gaining a functional understanding of what’s happening in the brain, of how the mind arises from it and how its subsystems interrelate, is far harder, but the reward could be a much more efficient model. And it may be the only way to have a copy of a mind that isn’t hopelessly slower than the original.
October 31st, 2015 at 2:53 pm
“You used a high end synapse count estimate, but most of what I’ve read puts it closer to 100-150 trillion.”
My reference was the Wikipedia Neuron article:
But, yes, I am going for a “high-end” brain. The implication being we’d want to cover the full spectrum of the human race, including three-year-old children.
“I also suspect that the link address sizes could be mitigated by the way neurons are clustered…”
There are definitely strategies that can reduce brute force estimates. In the general case, it’s hard to restrict any given neuron from connecting with any other given neuron, but there are specific cases where you can say that this population of neurons only connects with that population of neurons.
(A larger general model usually runs faster than a smaller one with special cases, so that’s one consideration.)
“Even if we stick with a neuron global address space, I only count 40 necessary bits (5 bytes),…”
That only indexes up to a trillion. In our model, the pre-synaptic axon connects to the post-synaptic dendrite (not the neuron), so the potential address space is the one quadrillion synapses, not the 100 billion neurons.
There’s an under-the-hood implementation issue I didn’t go into. You’re a programmer, so this won’t be black magic to you:
The neuron model has a variable size. Some neurons only connect to two other neurons, some connect to up to 10,000. The average is 7,000. We have two basic choices for a data structure: A
NeuronSynapseobject with variable size; or separateNeuronandSynapseobjects.In the latter case the connection model needs to account for the binding of
neuronobjects withsynapseobjects, and that takes bits. In the former case we end up with variable sized objects in the table (which means we can no longer index them, only address them.)Even so, to reduce model size, I’m making certain assumptions (e.g. all synapse records belong the neuron record immediately “above” (lower in memory than) them; that removes the need for a table linking synapses and neurons). OTOH, that means I need two bits per (64-bit) object to mark the object as: Neuron, Axon, Dendrite, Synapse.
And, as you mentioned, there are certain speed advantages in using the native data size of a system.
“Accounting for neuron topologies and glial cells (and their topologies as well) might drive up the model size even higher.”
Absolutely! There are all sorts of factors that will affect model size and function. All I’ve tried to do here is stick a rough pin in a quantity that’s a rough guess at K-complexity (as much from my own curiosity as anything else).
“I’m uneasy that this is the path that mind uploading would ultimately take.”
Yes, it’s difficult to see how it could be accomplished in this framework. (But as I’ve said before, I think mind uploading is the least likely of the AI goals and the most difficult, if even possible, to accomplish. Creating new minds — something we know nature does — is a far closer goal, I think.)
“[T]here are indications that [Moore’s law] already slowing down.”
Indeed. The 2 TB drives have been out for a long time (although I guess they do go up to 3 TB). We’ve pretty much reached the limit of transistor and magnetic domain density. We seem more or less topped out on CPU speed, too. We do make small advances, but it feels like the top part of the ‘S’ curve in many ways.
October 31st, 2015 at 5:57 pm
Oops, I stand corrected on the 40 bit thing. You’re right, to account for a quadrillion synapses, we’d need 50 bits. That’s what I get for fast and loose use of the calculator.
I tend to think we’ll get there with the storage. Current technologies might be hitting their limits, but again, based on nature doing it, we know we can go smaller and denser, although read / write performance might suffer. (DNA, for instance, is stored at the molecular level, but it takes a long time (24 hours) for cells to run through it.)
November 1st, 2015 at 8:26 am
Likewise. Things that can be seen as engineering problems usually get solved (although we do encounter the occasional possible, but intractable problem). Humans can access their own brains fast enough to be functional, so super-dense memory (that can be accessed in reasonable time) must be feasible.
January 12th, 2019 at 11:51 pm
It’s always bugged me a little that I never showed the size of the human synapse space in base ten. In the previous post, I showed the computer connectome space in both base two and ten, but for some reason in this post I just used the base two value.
For the record, it’s:
216,000,000,000,000,000 ≈ 104,800,000,000,000,000
Compared to the computer connectome space:
22,500,000,000,000 ≈ 10750,000,000,000
Rather a difference! 😀
May 12th, 2022 at 12:09 am
Insane, unimaginable numbers in any case!
September 8th, 2023 at 10:58 am
[…] Last week we took a look at a simple computer software model of a human brain. (We discovered that it was big, requiring dozens of petabytes!) One goal of such models is replicating consciousness — a human mind. That can involve creating a (potentially superior) new mind or uploading an existing human mind (a very different goal). […]
June 13th, 2024 at 5:58 pm
[…] As an aside, note that S is large (either 50 giga or 250 tera). M is even larger. [See: The Human Connectome] […]