 The computer what? Connectome. The computer’s wiring diagram. The road map of how all the parts are connected.
The computer what? Connectome. The computer’s wiring diagram. The road map of how all the parts are connected.
Okay, granted, the term, connectome, usually applies to the neural wiring of a biological organism’s brain, particularly to the human brain. But the whole point of this series of posts is to compare a human brain with a computer so that we can think about how we might implement a human mind with a computer. As such, “connectome” seems apropos.
Today we’ll try to figure out what’s involved in modeling one in software.
The ultimate goal — our consciousness running as software in a (Turing) machine — assumes our consciousness is software that can be run in a (Turing) machine. That much seems a tautology.
 If the assumption is correct — and it could be — then there is some (abstract) Turing Machine (TM) that implements the algorithm of consciousness. That follows from Church-Turing (C-T).
If the assumption is correct — and it could be — then there is some (abstract) Turing Machine (TM) that implements the algorithm of consciousness. That follows from Church-Turing (C-T).
Therefore: modeling a much simpler TM (such as a computer) offers a useful baseline to compare against the requirements of trying to implement a human brain.
That initial assumption, plus C-T, means the computer is just an (extremely) inferior version of a brain. If we could figure out the right algorithm, any computer could run the “mind” program.
One of the brain’s notable features is that it is a huge, massively inter-connected network (the human connectome). As practice, and for comparison, we can first try to model the computer connectome.
It turns out that, at the system level, there actually isn’t much to it. If you’ve ever worked with PC hardware, you know a lot of it is things plugging into other things. There are only so many wires in a plug!
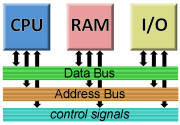 When we looked at Von Neumann architecture, we saw that most computer components are connected via a common system bus.
When we looked at Von Neumann architecture, we saw that most computer components are connected via a common system bus.
That bus divides into a data bus, an address bus, and various controls signals. (And power.)
A modern computer may have up to 64 bits (wires) in both the address and data bus (128 total). Control signals likely number in the dozens.
So we have a basic system connectome comprised of a bunch of (highly) functional “black boxes” all connected to a common system bus with maybe 200 or so wires.
But there’s a lot hidden in those black boxes. (Or is there.)
All of memory is a bit like a long picket fence. Each vertical slat is one memory location, but they all hang on the same horizontal rails. Each memory location connects (albeit virtually) with the data bus.

The vertical red lines are the data bus. The short horizontal lines on the right are the memory cell select lines.
Control circuitry in the memory blocks uses the address bus to determine which memory location actually accesses the bus.
Conceptually this amounts to a logic circuit connected to the address bus and with one wire leading to each memory location.
Say a computer has 1 gig (one-billion memory locations) of RAM. Our wiring diagram for that has the data bus connecting to each one, the address bus connecting to the address decoder, and one billion wires connecting from that to the memory cells.
One way to look at that is that we are describing one billion (locations) times 64 data bits plus another billion connections for location select, plus the 64 address bits. So 65 billion (and 64) connections.
Except, as the previous paragraph shows, all those connections — because of their regularity and repetition — can be described very simply.
Whatever value the 64 data bits have, all one billion RAM cells see the same value. Describing the select lines is as simple as saying “address #0 maps to cell #0” and so on.

Microphoto of a RAM chip. Note the regularity and repetition. Each bit of each memory cell is the same electronic circuit. The light and dark blue bands are control circuits.
If I wanted to model what’s going on inside the RAM cells or inside the address decoder, that’s more complex, but you might be more surprised at how complex it actually isn’t.
For one thing, if I’ve described one memory cell, I’ve described all one billion.¹
The I/O modules have a complexity on par at least with a memory address decoder (that is, they’re mostly logic circuits).
More complex I/O modules can be sub-systems with their own processor (which makes them capable of anything you can program their hardware to do).
The CPU, obviously, is the most complex module, and as I mentioned before, recapitulates the Von Neumann architecture within itself.
The complexity of our wiring diagram depends on how far down the rabbit hole we want (or think we need) to go. The system level — highly functional black boxes on a system bus — isn’t very illuminating and certainly not a real model of the computer.
Let’s instead assume we do need to go deeply down the rabbit hole and model the computer at a transistor level. We could go further still, but the transistor level and its interconnections is as far down as we can go and still see the computer functionality.²
Modern CPU chips are clocking in at around a billion transistors (with really high-end chips, as many as five). One approach is to list every transistor (or other singleton electronic component, diodes, capacitors, etc.) along with what it connects to.

Photo of an (old-fashioned) transistor and its diagram symbol. Note the three leads.
Transistors have three connections, most other components have two, so a two-way list (that describes the connections from both directions) requires a table of up to six billion connections.
Each one looks like: “transistor #76018 (lead 3) connects to transistor #105629 (lead 2)” (Note that this connection would also have a reverse connection in the table.)
The connection map isn’t enough, of course. We also need to characterize the behavior of those components. Fortunately, one transistor works just like another (likewise other components), so describing one (as with memory cells) describes them all.³
So as far as the complexity of a computer, we have a six-billion entry table describing the CPU connectome, plus various models of component behavior, a system bus connectome (which is simple), a model of a memory cell, and whatever the complexity of the I/O modules is. Let’s say it’s comparable to the CPU.
 So we’re talking roughly a table of about 12 billion or so numbers. Our “address space” — the total number of connections — is only in the billions.⁴
So we’re talking roughly a table of about 12 billion or so numbers. Our “address space” — the total number of connections — is only in the billions.⁴
Keep in mind, this is what it takes to describe a computer that’s just sitting there not doing anything (including even being turned on).
We’ve only described the static system.
But consider that we’ve described a high-end computer using a table of connections and a small set of component models.
Even if we’re off by an order of magnitude, we can still fully describe a (static) computer in, say, 480 gigabytes⁵.
Another way to view this is to imagine the B&W bitmap that is the schematic of the entire computer and consider the compressed size of that bitmap (48–480 gigabytes doesn’t seem a bad estimate).
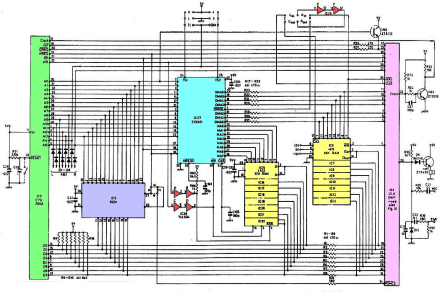
A system-level wiring diagram for a complete, but very simple (Z80), computer. Note how basic the wiring actually is. But the colored boxes contain many components (and wires) inside them.
But we haven’t described the software in the machine!
Even on the bitmap we imagined, the BIOS chip is just a square box. Our transistor-level connectome treats it as memory, and all memory cells are treated under one model — a model that does not reflect the current state of the system.
That means our computer connectome (48–480 gigabytes) also needs a table of memory values, at least for some memory locations. Since we’re treating all disk space as memory, we effectively need a memory table comprised of all software on the system.
 We know a functioning computer requires BIOS and an O/S, but applications are optional, so it’s hard to quantify how much size to grant them.
We know a functioning computer requires BIOS and an O/S, but applications are optional, so it’s hard to quantify how much size to grant them.
We could just treat the entire address space, disk included, as state we need to preserve.⁶
A high-end system might have a two-terabyte drive. Let’s assume that plus 16 gigabytes of RAM and one more of BIOS.
That gives us a memory state space of 2.017 terabytes plus up to 480 gigabytes for the connectome.
So our (static) model of a (high-end) computer weighs in at about 2.5 terabytes.
The good news is that, because we went low-level, and because the behavior of electronic components is fairly simple and well-understood, and because binary is just ones and zeros, creating a dynamic model that makes the static model actually function is relatively easy.⁷
Note that a real computer with a two-terabyte drive, 16 gigs of RAM, and a high-end CPU, has roughly the same information level.
 That’s no coincidence.
That’s no coincidence.
Information, especially binary information, has a minimum size. The real thing, a sufficient image, or a software model, all have roughly the same information content.
Something else we can consider (and compare to the brain) is what it takes to make a snapshot of a working computer at any given instant. What would it take to freeze my (working) model, save it to disk, and reload it later to resume where it left off?⁸
In a computer, transistors are either off or on. That means a snapshot of a billion-transistor CPU requires saving one billion on-off states.
If our transistors have an order (one is first, another is second, and so on), we can just list the one billion on-off states in that order. Since this is a model, our transistors do have an order, so a snapshot potentially only takes about 125 megabytes.⁹
 If we save an unordered list, each state needs to be labeled. (Which makes each state mostly label: For example, 31 bits to say which transistor plus one bit to record its state.)
If we save an unordered list, each state needs to be labeled. (Which makes each state mostly label: For example, 31 bits to say which transistor plus one bit to record its state.)
Then we’re talking a gigabyte for a snapshot.
There are other transient states we might need to capture in a snapshot, mainly in the memory and I/O logic. (Many of these depend entirely on states output by the CPU, which makes saving them redundant.) Still, let’s allow our snapshot up to two gigabytes.
Something to consider is that every cycle in a running system (billions per second) is a transient snapshot, so a computer sitting there being a computer generates billions of multi-gigabyte “pictures” every second!
I’ll leave you with what might seem like a very large number.
Given the possible number of states in the system (let’s call it 2.5 terabytes), what is the total configuration space — the total number of different snapshots possible?
Since the states are binary (zero or one), it’s: 2s
Where s is the number of states. So what’s 22.5 terabytes ?
A number that takes three-quarters of a trillion digits just to write down. That’s how many different snapshots your PC can generate!
[1] A physical disk drive is much more complicated, but from a modeling perspective, it’s just memory, and we can pretend it’s RAM.
[2] Down at, say, the electron level computers work pretty much like everything else in the world does. The interconnections define the computer as much as the components do.
[3] In point of fact, there are different types of transistors that operate different ways, but the ones used in computers are like switches and are basically all the same until you get down to a serious EE level.
[4] A table of up to four billion transistors can be addressed with 32-bit numbers.
[5] Assume 12 billion is wrong by a factor of ten, so 120 billion connections are required. At 32-bits (four bytes), that’s 480 gigabytes.
[6] After all, there’s no reason unused disk space shouldn’t be part of the software model.
[7] Compared to, say, a model of the weather, a living cell, or even a video game.
[8] Many computers today can actually do this.
[9] One billion states divided by eight bits per byte.













October 30th, 2015 at 11:03 pm
That is nice information. thanks
October 31st, 2015 at 1:13 am
You’re quite welcome. 🙂
November 1st, 2015 at 8:50 am
If you’re wondering how we get from a very large power of two to it’s very large approximate equal as a power of ten, it’s done with logs. We want to solve this:
And we want to solve for x. So we can consider that:
Which is:
Which means that:
And we can divide both sides by log2 10 to get:
And that can be solved, since log2 10 ≈ 3.32192809489, so:
And, therefore:
November 2nd, 2015 at 12:07 pm
As a side note, before I went to Google and typed in [log2 10] — to which Google gave me the answer used in the comment above (3.32192809489), I’d come up with a rough estimate of log2 10 using a technique similar to the one above.
I have an arbitrary precision calculator capable of giving me an exact answer to:
Taking the log of 22,000 gives the number of digits in the result. That lets us express it as a(n approximate) power of ten:
Now we can rephrase this as we did before:
Which means that:
This time we divide both sides by 3011:
Which finally gives us:
Which is an error between the Googled value and the rough estimate of only 0.000772332684. Not bad!