 We started with the idea of code — data consisting of instructions in a special language. Code can express an algorithm, a process consisting of instruction steps. That implies an engine that understands the code language and executes the steps in the code.
We started with the idea of code — data consisting of instructions in a special language. Code can express an algorithm, a process consisting of instruction steps. That implies an engine that understands the code language and executes the steps in the code.
Last time we started with Turing Machines, the abstract computers that describe algorithms, and ended with the concrete idea of modern digital computers using stored-programs and built on the Von Neumann architecture.
Today we look into that architecture a bit…
An algorithm is an abstraction of the state diagram that defines it. If you understand the diagram (if you can read the flowchart), you can trace through and execute the algorithm yourself — you can be the engine.[1]

Code written in “Java”
Generally, if you know the code language, you can execute an algorithm using that code in your head (or with the aid of pen and paper). Programmers routinely scribble their thoughts in pseudo-code, a pretend language no computer actually understands.
One distinction among languages is how easy or hard it is to follow along with the computer. (Attempting to execute a suite of algorithms manually becomes a formidable — but theoretically possible — task.)
The whole point of programming languages is to elevate the level of abstraction to a point where humans can manage it (and in those abstractions discard a lot of details). The code the computer actually uses is made of just ones and zeros.[2]
The thing about computers is that they are extremely simple-minded devices. Simulating a computer is actually very easy, because when you come down to it, there’s not much to them. Here’s the executive summary on what computers can do:
- Input some numbers into them.
- Do math or logic on those to make new numbers.
- Output the resulting numbers.
That’s it. That’s all computers do.[3]
The thing is, they do it really, really, really fast. And you can make them output useful numbers, even numbers that do things (like control machines or make pictures).
 But they’re still just over-grown calculators — keep that in mind.
But they’re still just over-grown calculators — keep that in mind.
My ultimate goal here is to characterize the complexity of a computer but doing that requires understanding more about their architecture — the topic de jour — so let’s get to it.[4]
Your average digital computer has three fundamental parts (besides control circuits and power supplies and other miscellanea):
• The Processor (the “engine” or “brain” that executes code) — often called the CPU (central processing unit). All the math and logic happen inside this. The processor also controls (directly or through co-processors) the operation of the system.
• Storage, also called memory. Exactly as the name implies, a place to store stuff. In particular, the code and data for the system. Memory includes both short-term (RAM) and long-term (disks, et al.) storage — any place you can stash data.
• I/O (Input/Output). The “senses” and “muscles” of a computer. This is how data (including code) gets into the system and how results of processing get out. Common examples include keyboards, mice and other pointing devices, video displays, and printers, but that only scratches the surface of I/O devices.
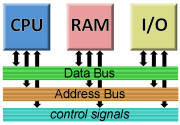 All three of these are connected via a common parallel data highway mainly consisting of the address and data buses (and some control lines).
All three of these are connected via a common parallel data highway mainly consisting of the address and data buses (and some control lines).
In a sense, the CPU, the RAM, and the I/O, all live on the same “street” — the address bus carries the “house number” of the one the CPU is talking to at any given moment. (Those moments, as mentioned, are very, very brief.) The data bus, obviously, carries the data.
The “width” (number of wires, one per bit, usually a multiple of eight) of the address and data bus is correlated with a computer’s processing power. A wider data bus means more information exchanged each cycle; a wider address bus means more memory (the more addresses available, the more “houses” can be on the “street”).
One thing that’s interesting about this architecture is that it plays out again inside the CPU!

Micro-photo of a Zilog Z80 (an old 8-bit CPU chip). It shows the complexity of even a very simple processor. (That it looks like a computer motherboard is not coincidence!)
The Processor is a self-contained computer with its own microcode engine (arithmetic and logic units that perform operations), local memory (cache and registers), and I/O (to connect outside the chip).
The width of the data bus inside the CPU is even more correlated with processing power than the system data bus. A bigger data bus means the processor can calculate with larger numbers.
References to “32-bit” or “64-bit” computers usually refer to the size of the CPU data bus.
Typically, the system buses are the size as the CPU buses, especially the data bus, but there are exceptions.[5]
We’ll come back to the CPU internal architecture in a bit. For the moment, we’ll stick to the system level.
Let’s suppose the code the computer is running right now is tallying up a sum of some kind and has reached the point in the algorithm where it needs to add an amount to the running total.
The programmer who wrote the code likely used a programming language with a high level of abstraction that allowed them to write a human-readable fragment of code something like this:
total := total + amount
This says to take the current value of the total variable and the value of the amount variable, add them together, and put the resulting sum back into the total variable. (The “:=” part means put the value on the right into the object on the left.)
Remember that variables are code objects that act like scratch pads for calculation. We’ll assume some memory location is known to the code as total and another is known to it as amount. (That is, it knows the address of those objects in memory.)
The code running in the computer looks something more like this (a register is a special memory location inside the CPU):
LOAD register-1, [total] LOAD register-2, [amount] ADD register-1, register-2 STOR register-1, [total]
Note that this is still an abstraction for us humans to read and discuss. The CPU is actually just reading a code stream of binary numbers — bits — from memory.
An application called a compiler converted the programmer’s high-level source code into low-level assembly code similar to this so the CPU can run it. This low-level code represents what the CPU can actually understand and do.[6]
Therefore, we can view these steps in light of the earlier list of the Three Things Computers Can Do:

Way beyond the Z80!
The first two steps read numbers from memory into the CPU (ability #1). The third step adds those two numbers together resulting in a sum (ability #2). The last step writes that sum back into memory (ability #3).
That’s it. That’s all computers do.
We’ll wrap this up by jumping inside the processor to see how it handles those four instructions internally.
The CPU has been reading instructions and comes to the first LOAD instruction. It looks this up in an internal table and finds (and runs) a micro-program for doing a LOAD instruction.
The microcode knows that following the LOAD instruction is the name of a target register and a memory location, so it reads those (which may require using the very process described next).
To read from a memory location the microcode goes through the steps to place the memory address specified (total) onto the external address bus. (That is: it outputs a number from the CPU!)

Bus wire highway!
Then it waits for system memory to access that location and put the value it finds on the data bus.
(This is a real-world operation that takes a tiny fraction of time. Signals on the control bus tell the processor when the data is ready.)
Finally, the CPU reads the returned value off the data bus and into the register specified. (It inputs a number!)
The next instruction is another LOAD that inputs a different memory location into a different register, but the process is identical otherwise.
The ADD instruction also invokes a micro-program from the internal table (all instructions do). In this case, the next two items in the code stream name two registers that hold values to be added.
The CPU uses its arithmetic logic unit to perform the addition with those values and places the result of the addition in the first register named (which destroys the value — the previous total — it originally had).

Safely stored in RAM!
The STOR instruction is the reverse of the LOAD instruction.
The CPU again outputs the memory address, but this time it also outputs the register value to the data bus. The system memory takes that value and writes it to the memory location specified.
(Again, control signals tell the CPU when the operation is complete.)
If you think this sounds involved, be advised that by today’s standards it’s quaintly old-fashioned and simplistic. Modern CPUs are hideously involved to the point that writing even halfway decent assembly code is best left to the experts who design modern compilers for those chips.[7]
As the same time, as the saying goes, “Calm Down! It’s only ones and zeros!” Underneath all the complexity is a simple machine that does only three things.
Fast. Oh, so blindingly fast!

Micro-photo of part of a modern CPU. Pretty!
[1] In fact, that’s one of the values of flowcharts. It lets us see the algorithm we’re building and pretend to be the computer that will run it. (Another value of flowcharts is they let us communicate algorithms with other humans.)
[2] “Assembly” languages are an extremely low-level abstraction based directly on the binary code language the CPU uses. They give humans a fighting chance as working with the actual computer code run by the CPU:

As you can see, it’s an esoteric language. The numbers down the left-center are the hexadecimal versions (an abstraction) of the actual binary codes used by the CPU. The “assembly” language is the strange text filling the right half. (The numbers on the far left are the memory locations of this code.)
[3] The word, computer (one who computes), is just another word for calculator. (Historically, the word referred to humans who had the task of calculating things.) Computers calculate. Using numbers.
[4] In related Sideband posts, I plan take you way down the rabbit hole to the logic gates and transistors that make it all work.
[5] For example, a system that doesn’t need a large address space might not bother with a full-sized address bus.
[6] Which means a given dialect of assembly code is particular to a given CPU.
[7] And makers of computer viruses which need the low-level “close to the metal” access assembly allows. And therefore, likewise, makers of anti-virus software. It’s a very esoteric field!
∇














October 24th, 2015 at 4:47 am
I used to write games in Z80 assembly language. That’s why I never had a girlfriend as a teenager. 8-bit processing was the best!
October 24th, 2015 at 11:17 am
Yes! I loved the Z80! As it turned out, I wrote a lot more assembly code for the 6502 in my Commodore, and more yet for the 8086’s inside various MS-DOS boxes, but that Z80 was a sweet, sweet little chip.
(Your comment made me realize that, in fact, I owe my mid-1980s transition from hardware to software at The Company to an assembly-level TSR (remember those?) I’d written for use by co-workers. It’s what got them to realize I did software, too. I’d never realized I owed much of my career to 8086 assembly code! 😀 )
October 24th, 2015 at 3:26 pm
I was an Atari 400 kid myself (6502 chip). We started with 16 kilobytes of RAM and 300 baud tape storage. Those were the days when it was still possible to pretty much learn everything about a machine, all its registers, data ports, everything. I remember a book I had that listed the entire source code for the machine’s ROM operating system. (Really just a primitive BIOS by today’s standards.)
October 24th, 2015 at 5:03 pm
I never had a chance to muck about with an Atari, although I understand they were neat little machines. My very first computer was a Timex Sinclair Z80 with, IIRC, 1 KB of RAM on board. I bought a 16 KB expansion module that plugged onto the back. And, yeah, off-line storage was a cassette tape player. And it had an RF connection for your TV as a monitor.
Even the PCs, up until about when windowing O/Ses really took off, were machines you could master including the operating system. I know what you mean about BIOS listings. I had a similar reference for the Commodore machines. (And later for the IBM PCs and MS-DOS.)
I stopped trying to keep up with assembly programming after the 80386! Higher-level languages are a lot more fun! Even with lots of macros and a rich library, assembly program gets really tedious.
October 24th, 2015 at 6:54 pm
I remember reading about the Sinclairs and thinking how cool they looked, particularly for the price.
The only substantive assembly language programs I wrote were on the Atari. I dabbled with assembly on early PCs but, like you, the availability of compilers (which had only been a rumor in my 8-bit world) and high level languages turned out to be much more of a clarion call, particularly once I started making money with programming. I did read about the 386 instruction set, mostly out of curiosity about the ring 0-3 stuff, but never had occasion to do anything with it.
October 25th, 2015 at 12:45 pm
In school I was playing with an IBM 370 and a DG Nova, so the Sinclair had a certain toy-like feel, but it was the first computer that was all mine, so it was pretty thrilling. Then it was the Commodore 64, the Commodore 128, and finally my first MS-DOS machine (which I built from parts).
Both the Commodores and MS-DOS came with BASIC, so I did a lot of BASIC programming in my early days, too. But, as you say, there were compilers available in the MS-DOS world, so there was some Pascal, a lot of C and C++, Visual BASIC (which was delightful), eventually Java (which I initially hated but came to love), and most recently Python (which I just adore). Those were the languages I did most of the heavy lifting in, but I’ve always had a fascination with programming languages.
(FWIW, I just did a set of posts on my programming blog (The Hard Core Coder) about some toy languages I doodled. I’m trying to decide if some of the more programming-related stuff associated with the series of posts I’m doing would be better done there than here. It fits there better, but means sending readers off to my other blog.)
October 25th, 2015 at 3:24 pm
I remember looking with envy at the Commodore 64s and related machines. We started with the Atari 400, upgraded to the Atari 1200 XL (a disappointment), before making the jump to IBM compatibles with a Tandy 1000.
My own pattern was something like Atari Basic, 6502 Assembly, Pascal, dBase / Clipper, C, SAS, C++, VBA, Visual Basic, COBOL, Lotusscript, Java, C#, and VB.Net, with lots of dabbling in other languages along the way. My Dad did a lot of stuff in Microsoft QuickBasic in the 80s and early 90s, a good deal of which rubbed off on me.
On where to put the programming stuff, my thinking would be that it depends on your target audience. I know I’d have a hard time getting into programming in enough detail to entice programmers but still hold on to general readers, but then you’ve taken some pretty deep dives here before.
October 25th, 2015 at 4:46 pm
Yeah, I have. This blog serves to document things that interest me, and sometimes things do get a bit deep. I try to stick the really technical stuff in Sideband posts to warn off the faint of heart. 🙂
The programming blog assumes an interest in, and some exposure to, programming. I’m not writing for a general audience at all there (one reason I started that blog is so I didn’t have to — it removes the temptation to do that here).
I’m thinking the post (or posts) about state tables and state engines goes on The Hard Core Coder. (At one point in my career, I fell in love with state engines, and used them everywhere I could — which turns out to be a lot of places. I’ve meant to write about them on Coder for a while.)
The post (or posts) about how transistor logic works will probably be a Sideband (or two) here. I haven’t blogged much about my hardware background… yet. 🙂
Looking at your list, the only one not familiar to me was SAS, which (according to Wiki) looks like it might be similar to SPSS? My cousin used that for a while when he was teaching restaurant management (I mostly just watched and tendered unasked-for advice 🙂 ).
Did you ever get into the really different languages (like: Smalltalk, Lisp, ML, Haskell, Prolog, Forth to name just a few)? They can be real eye-openers, can’t they!
And then there’s languages like Malbolge and Brainfuck…
(I have my own mind-twister language: BOOL and a blog to document it. Don’t look… It’s a language only a father could love! XD )
October 25th, 2015 at 6:11 pm
SAS is definitely an alternative to SPSS. My university has used it for administrative reporting for years. It has a scripting mode that allows you to quickly manipulate and do statistical transformations of data. I briefly used SPSS in grad school, but didn’t do any programming against it, but it’s heavily used by researchers.
I did read a little about Smalltalk when I was learning OOP, although ultimately I cut my OO teeth with C++. I know the others mostly by reputation. I had a friend who dug pretty seriously into Forth in the early 80s.
I forgot Javascript on my language list, although I never used it as extensively as it’s used in modern dynamic web UIs.
Wow, I’d never heard of Brainfuck. Looking at the Hello World program…the language is well named.
Looking forward to the transistor logic posts. I have an understanding of it, but not so thorough that I couldn’t learn some new things.
October 26th, 2015 at 11:24 am
Statistics is an area of programming that, despite my love of math, I never explored. Likewise numerical analysis, which I know just enough about to know I’d be out of my depth. Floating point has some esoteric gotchas!
C++ was my first OOPL as well. I wrote a lot of code using it. And it was really the way C++ worked under the hood — just translating C++ into (ugly) C for cc to compile — that lit a light bulb in my mind: Say… that means I can write OO code for C… or even assembly!
Which was true, and I did. I actually had object-oriented libraries of C and MASM code. Virtual methods, the whole nine-yards. There was a manual aspect to it, and rules you had to enforce yourself, but it did do what any abstraction does: made writing new code easier.
And, man, did it ever teach me about how to implement OOPLs!
I’m convinced due to a lot of data points over the years that programmers who learned assembly are better programmers. Knowing something about how the machine actually works seems to create a better understanding of how to write code. I think, too, that knowing something about how languages work and are implemented can lead to better programming chops.
What’s interesting about languages like Smalltalk or Lisp (or Forth or any of the functional languages) is that they expand your understanding of what a programming language is. If someone has spent most of their career with, say, C, C++, Perl, PHP, JavaScript, and Java, then they’ve basically used the same language throughout (a “curly-brace imperative” language). Even the various BASIC dialects keep a programmer well within the imperative programming paradigm.
JavaScript was the language I used to recommend as a good first language for newbies! It’s simple enough to learn fairly quickly, but rich enough to do some serious programming. And its association with browsers means you can get interesting and fun results quickly and it comes free with your system. There’s also that a number of systems use it (or, strictly speaking, ECMA 262) as their automation language, so it can be a useful resume bullet point.
These days I recommend Python as a first language because it’s just so much fun. 🙂
October 26th, 2015 at 12:45 pm
Totally agree that knowledge of assembly makes for better programmers. I can’t tell you how many times simply understanding how memory actually works has allowed me to diagnose problems other programmers were stuck on. And much of the confusion beginning c coders have with arrays, pointers, and bit-wise operators is nonexistent if you understand the rudiments of assembly.
I had the same epiphany on OO and procedural languages. In my case, it came from studying the Windows APIs and realizing that handles and their related calls were essentially objects. (They started out as pointers to structs, until programmers started using them to bypass the API calls, leading MS to change them to be indices to internal tables.)
Never tried to implement OO in assembly, although I do remember reading an article years ago on implementing structural programming in it using macros.
If I ever get interested in programming again, I’ll definitely have to check out Python. (Interest for me wanes and waxes over the years. Not doing it in my job on a daily basis anymore, I’m currently in a wane phase.)
October 26th, 2015 at 3:15 pm
“And much of the confusion beginning c coders have with arrays, pointers,..”
Oh, my, yes! Once you’re gotten assembly under your belt, pointers aren’t mysterious at all! (They do call C “high-level assembler” for good reason.) I’ve taught beginning C programming, and another stumbling block I’ve noticed is fully internalizing that the following two expressions are identical:
(In fact the first one is just syntactical sugar; compiled code looks like the second one.) Understanding why those are the same thing helps with a lot of the lurking surprises C has for the unwary. And that equivalence sort of goes with assembly territory.
(I get a kick out of the many metaphors that compare C to other languages: it’s a “chainsaw” or a “stripped down sports car” or “like driving on a dark mountain road with no guard rails.” And they’re all true. 😀 )
((I was part of the online C community in USENET, and C programmers like that C is a chainsaw — and, in fact, chainsaws are great for certain tasks. They tend to see themselves as hardy, fearless, studly programmers, and you’ll have to pry their beloved C out of their cold, dead hands. The rest of us wonder why those fools are juggling chainsaws. Don’t they know that’s dangerous?! XD ))
“…realizing that handles and their related calls were essentially objects.”
That’s true. What I did went beyond that. I implemented a framework that bound methods to structured objects that allowed virtual methods and, therefore, genuine object hierarchies. You could write routines taking a base object and pass them a derived object just fine.
You’re a programmer; I can get technical! Each object had a base type that was just a pointer to a table of methods. So every object in the system can be treated as that base, and you can get that pointer. Within a class, a given method ends up being a known index into the methods table.
You can see, I’m sure, how it works. Calling a method on an object means de-referencing the pointer and indexing the table of methods. Assuming a valid object was passed, you end up calling the right method without actually knowing the object’s true type.
In C++, that’s all done under the hood by the language. In C or MASM, you create the tables by hand, although macros help.
(Heh! Speaking of macros to help coding… there was some long-ago freeware open source app — I can’t recall what it was right now — where macros defined BEGIN as { and END as }… just so the C code could look more Pascal-y. At first I thought it was a neat idea, but smarter programmers read me the riot act on that one. It’s a stupid idea that just obfuscates things — a cardinal sin in programming. In fact, in my book, the cardinal sin.)
“If I ever get interested in programming again, I’ll definitely have to check out Python.”
Not that I’m trying to sell you on Python. (It’s one of those languages that generates exuberance and enthusiasm in users, so we tend to go on a bit sometimes.) But I’ll give you an example of just one reason it’s cool:
WordPress fixed a problem involving exporting your blog to XML if your blog is above a certain size (this appears to include post length and comments, so it’s not predictable when a given blog becomes too big). Their workaround has been having their online support people do an extract into a multi-XML ZIP file and sending you an email with an evaporating link (good for seven days) to the ZIP.
Just recently (BRAVO WP!), they implemented that as a process. Now when you export, it does what I just described and sends you an email automagically. Love it!
But I have a small suite of XSLT I wrote that converts the XML to nice HTML pages listing all my posts, all my images, etc. But now the XML comes in parts! My XSLT engine needs a single XML file.
Twenty minutes of Python coding later, I have a little “app” that stitches those XML files together into one massive (24 megs!) one. But now my XSLT works and I can have my HTML listing pages again!
Python is great for little chores like that. I used to use Perl for that sort of thing (and Perl is cool in its own way, but it looks too much like line noise), but Python is like switching from a great old Chevy to a Tesla or something.
October 26th, 2015 at 5:35 pm
On your OO table, did you ever read about Microsoft’s OLE/COM using the original C API? They exposed interfaces as essentially arrays of void pointers (each of which pointed to a function). When I first learned about it, I wondered why they had done it so ugly in C instead of C++, but then I learned that C++’s implementation of its vtables is not part of the language spec (compilers could implement it anyway they want), and MS needed the interfaces to be in a tightly controlled format to keep it cross language.
Hmmm, your remarks about the WordPress export made me realize that I hadn’t exported in a very long time. Just did it, and it emailed the file to me. I wonder if they do that for everyone now, or if my blog has exceeded that size threshold.
I have a test blog that I use to test widgets (which I haven’t played with in ages). When I first set it up, I exported my production blog and imported it into the test blog. I was appalled by how poorly a lot of the comments came across. I hope WP has improved on that.
October 26th, 2015 at 6:31 pm
“MS needed the interfaces to be in a tightly controlled format to keep it cross language.”
Yes, exactly. COM is language agnostic, so it doesn’t use features of any language. It even has all its own data types. And it’s cross-network, which also constrains it. I like the general design, the idea of IUnknown, the marshalling of data, and have used it in other places.
I have written code that implements the I/F, but mostly I’ve used it to create new Excel and Word documents programmatically (which, if you want nice formatting gets long and rather tedious).
It is kinda fun to poke around in the COM hierarchy of something like Word or Excel. It gives you a sense of the internal model the app uses.
(You’ll get a kick out of this: I had a big fat book that explored MS COM in great detail, and early on it defines the over-applied — to the point of being meaningless — term “Active-X” to mean: “Microsoft! Warm, fuzzy, good!” XD )
“I wonder if they do that for everyone now, or if my blog has exceeded that size threshold.”
You know,… I wondered the same thing. I just went and exported both my other (very small) blogs, and in both cases, it just saves the XML file.
“I was appalled by how poorly a lot of the comments came across.”
Wow, that’s a bummer to hear! I hope they’ve improved that, too! (There’s some chance they have. WP is definitely a work in progress. The download thing is the first big change in a while that’s really worked for me. Oh, and another recent one! Did you know you can now remove subscribers? One of these days I’m going to do some serious housecleaning!)
October 26th, 2015 at 5:13 pm
“…until programmers started using them to bypass the API calls…”
I forgot to mention: The next time someone complains to you about how bloated Windows is, here’s one reason why. MS goes way beyond the line in maintaining obsolete supposedly internal data structures — to the extent of populating them with valid data even though nothing in Windows ever uses them — because so many programmers reverse-engineered some aspect of Windows and bypassed the API.
The could entirely reasonably say, “Tough Luck, you break the rules, you lose!” but what happens is people upgrade Windows and suddenly their apps break. Clearly got to be Windows’ fault, right? They worked fine before…
So they defend their brand by including junk data structures just so misbehaving programs can keep working. Windows essentially has junk DNA.
October 26th, 2015 at 5:48 pm
Years ago, when I first heard about that, I thought something like “Oh, how altruistic and far sighted of Microsoft.” Then I heard that their own programmers had bypassed the APIs first, taking advantage of their access to the OS team. Third party developers learned about those structures by disassembling Office.
Hopefully they’re not still maintaining the pre-NT structures. They were needed in 1993, but maintaining them today would just be an offense to software engineering.
October 26th, 2015 at 6:37 pm
“Then I heard that their own programmers had bypassed the APIs first, taking advantage of their access to the OS team.”
LOL! Why does that not surprise me. (I have heard there can be considerable competition and rivalry between groups at both MS and Apple.)
“Hopefully they’re not still maintaining the pre-NT structures”
I suppose it depends on the how established the offending app is. There are cases where a large business (with leverage, therefore) depends on an obsolete app from a third party no longer around, so they’re kind of stuck. Migrating off legacy applications can be an involved and expensive undertaking (my last position with The Company involved just that, and, oh, the stories I could tell… well, can’t actually tell, as such, but you know what I mean 🙂 ).