 Unless one has a strong mathematical background, one new and perhaps puzzling concept in quantum mechanics is all the talk of eigenvalues and eigenvectors.
Unless one has a strong mathematical background, one new and perhaps puzzling concept in quantum mechanics is all the talk of eigenvalues and eigenvectors.
Making it even more confusing is that physicists tend to call eigenvectors eigenstates or eigenfunctions, and sometimes even refer to an eigenbasis.
So the obvious first question is, “What (or who) is an eigen?” (It turns out to be a what. In this case there was no famous physicist named Eigen.)
The versions of the word are based on the German/Dutch “eigen” (“inherent” or “characteristic”). I’ve also seen it translated as “proper” for whatever that’s worth. Quite honestly, the name isn’t that helpful.
Explaining eigenthingies is a bit of a challenge. Not for lacking the words, but (as usual) in the difficulty of fully explaining what those words mean with simpler words. The idea isn’t the most obvious I’ve encountered.
One helpful tip: An eigenstate (physics-speak) is the same thing as an eigenvector (math-speak). A quantum state is a vector in Hilbert space. An eigenfunction and an eigenbasis are closely related (the former is roughly the same thing).
Another tip: Read carefully! It’s easy to conflate eigenvalue with eigenvector!
§
Okay, in words… An eigenvector is a vector that transforms to a new vector in two ways:
- An operator transformation on the vector.
- Multiplying the vector by a eigenvalue (a number).
To be an eigenvector, both operations must be possible and must result in the same new vector. (Note that the first case involves a matrix multiplication while the second involves a scalar multiplication.)
Understand this normally isn’t the case. When an operator transforms a vector, the new vector typically cannot also be obtained by multiplying the original by a numeric value.
To be eigen, all components of a vector have to change proportionally under the operator. That’s the only way to get a new vector that can also be created by multiplying by a number. (Proportional change of vector components is all that multiplying can do.)
 A good physical intuition is a rotating ball. The rotation is a transformation. We view the points of the ball as vectors being spun around. (Imagine an arrow from the center of the ball to every particle in the ball.)
A good physical intuition is a rotating ball. The rotation is a transformation. We view the points of the ball as vectors being spun around. (Imagine an arrow from the center of the ball to every particle in the ball.)
The component values of vectors being rotated do not change proportionally. One component changes according the cosine of the angle while the other changes according to the sine. Definitely not proportional, so none of the rotating vectors is an eigenvector.
But the component values for vectors on the axis of rotation do not change. That makes these vectors eigenvectors with an eigenvalue of 1.
(Because the vector length stays the same. If the ball were also expanding or shrinking, then the vectors on the axis of rotation would also expand or shrink, and then the eigenvalue would be the scaling factor.)
§
Note that an eigenvector can have multiple (even infinite) representations. There are any number of vectors of different lengths along the ball’s axis of rotation.
What we take to be the “characteristic” eigenvector is the “simplest” one. (Where “simple” generally means as close to normalized as possible. That is, a vector with length one pointing in the most positive direction possible.)
For the ball, all the vectors on the rotation axis (in either direction) are eigenvectors — multiplying them by the eigenvalue is the same as transforming them. Even vectors pointing in the negative direction, if multiplied by by the eigenvalue, remain pointing in that direction.
So here we say there is just one characteristic eigenvector, the unit vector pointing along the positive direction of the axis of rotation. All others are “echoes” of the characteristic one (they can all be created by multiplying the unit vector by some value).
§ §
So how does this apply to quantum mechanics?
Any observation we can make on a quantum system has a corresponding operator — which we represent as a (square) matrix with complex values. Such a matrix has eigenvectors with eigenvalues, each of which represents a possible measurement outcome.
An eigenstate is the state of the observed quantum system as a result of the observation, and the eigenvalue is the observed value — the quantity actually measured.
Further, a given observable can have many eigenstates, each with their own eigenvalue. The probability of an outcome depends on how “close” the eigenvector is the quantum state vector (“close” is defined using the inner product of the given eigenvector and the quantum state vector).
§ §
Time for some math. At the most general level:

Where T is a linear transformation (an operator), u is the transformed vector, v is an eigenvector, and λ (lambda) is an eigenvalue. Sorry about the Greek, but you may as well learn the notation and terminology.
The statement says the new vector u, created by T operating on the vector v, is the same vector we get from multiplying v by the eigenvalue λ. As mentioned, v and λ are special values that we calculate mathematically.
We represent this with a square matrix operator and column state vectors:

Recall that multiplying a vector by a numeric value, the eigenvalue in this case, multiplies each component of the vector by that value:
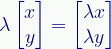
This is why the eigenvalue can only change the vector proportionally, which always preserves its orientation.
§
A trivial (and thus excluded) example is the zero vector:
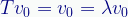
For any operator T and any value of λ, so the zero vector is never considered an eigenvector.
This is clear in the matrix representation:

Excluded for similar reason is the Zero operator, which maps all vectors to the zero vector:

Any vector multiplied by zero also becomes the zero vector, so in this case all vectors in the space are eigenvectors with an eigenvalue of zero, but this isn’t very useful.
(See previous posts about operators and transforms for more on this and the following operators.)
§
Another trivial example involves the Null transformation, which leaves all vectors unchanged.
In our simplified notation:

The eigenvalue is 1 because any vector multiplied by 1 is that vector. This example is trivial because the transformation in question, known as the identity, doesn’t do anything interesting.
In matrix operator notation:

For a less trivial example, consider the Scale operation. If we scale the space by 0.5, we have:

For any vector v.
To help understand eigenvectors I’m showing the transform and an image designed to show the transform dynamics:
Figure 1. The Scale(0.5) transform result (left) and dynamics (right).
Previously I had the original space on the left and the transformed space on the right. The original space is a given, so I’ve moved the transformed space to the left. The right side now shows the dynamics of the transform.
The blue lines show the movement of selected points under the transform. (Points on the X-axis are red.) The blue lines are not vectors, but the movement of the tips of vectors. For instance, under this transform, all the tips move inwards as their vectors shrink to half their original length.
Notice how the blue lines all move directly towards the center. Under the Scale transform, all the vectors in the space are eigenvectors, and the eigenvalue is the scaling factor (0.5 in this case).
It’s easy to see that the vectors on the axes remain pointing in the same direction, but it might not be entirely obvious it’s true of every vector. But note that each vector is the hypotenuse of a triangle. Changing the size of that triangle doesn’t change the angles, so all vectors retain their angle under the Scale transform.
§
Now consider the ScaleY transform, which scales the Y-axis but leaves the X-axis unchanged. As with the above example, we’ll scale by 0.5.
In matrix representation:
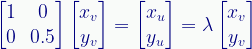
Which has this result and dynamics:
Figure 2. The ScaleY(0.5) transform result and dynamics.
The dynamics might be a bit confusing because they overlap. The important point is that all points move vertically towards the X-axis. Points already on the X-axis just stay where they are.
A crucial difference here is that it is not the case that all the vectors in the space are eigenvectors. Nor is there just one eigenvalue.
The reader is encouraged to pause for a moment and see if they can figure out what the eigenvectors and their eigenvalues are.
… Jeopardy Music …
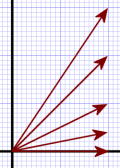
Figure 2a.
Recall from the Linear Transforms post how, under the Real transform, vectors that shared an X coordinate all collapsed into the vector that already aligned with the X-axis.
The Real transform is the same as a ScaleY(0.0) transform. Both reduce the Y-axis to zero.
In the case of the ScaleY(0.5) transform — or any non-zero scaling — the vectors in Figure 2a don’t collapse to the X-axis, but move towards it, as shown in Figure 2b.
The tip of each vector moves towards the X-axis such that the distance is reduced by half.
Figure 2b.
It should be apparent that, except for the vector along the X-axis, the angle does change under the transform — it becomes smaller.
(We can use trigonometry to determine how much. The angle is the arctangent(y/x). If we consider the top vector in Figure 2a, its slope is 3/2=1.5, so its angle is atan(1.5)≈56.3. In Figure 2b its new slope is 1.5/2=0.75, so the angle is atan(0.75)≈36.87. Note that 36.87 is not half of 56.3, so the angle doesn’t scale according to the transform.)
The important point is that — except for the bottom vector, which doesn’t change — none of the other vectors are eigenvectors because their orientation changes.
Vectors that already lie on the X-axis do not change under this transformation and, thus, are eigenvectors with an eigenvalue of 1. (We’d pick the X-axis unit vector, (1,0), as the the characteristic eigenvector.)
§
But we’re not done. What about the vectors that lie on the Y-axis?
Those vectors remain aligned with the Y-axis, but shrink to half their size. Therefore these vectors are also eigenvectors, but in their case the eigenvalue is 0.5. (Again, we pick the Y-axis unit vector, (0,1) as the characteristic eigenvector.)
So the ScaleY transform has two eigenvectors, each with their own eigenvalue:

Now I can mention that, given the matrix for some transform, the trace of that matrix is the sum of the eigenvalues for that transform, and the determinant of the matrix is the product of the eigenvalues.
In this case we have:

Our eigenvalues are 1.0 and 0.5, and, sure enough, 1.0+0.5=1.5=trace(M), and 1.0×0.5=0.5=det(M).
It’s a handy way to confirm we’ve found the right eigenvectors and eigenvalues, or, given some matrix, to determine what we need to find.
§ §
This has gotten long, so I’ll wrap it up. I started with the example of the rotation of a 3D ball. Now that should be a little clearer. The rotating vectors constantly change their orientation under rotation, but the axis vectors don’t.
Assuming the ball remains the same size, there is no scaling, so the eigenvalue is 1.
In the 2D Euclidean plane, the rotation around the origin has no eigenvectors, because all the vectors change (except the zero vector, which doesn’t count):
Figure 3. The Rotate(30°) transform result and dynamics.
The matrix representation is:

Where θ (theta) is the angle to rotate. For an angle of 30° we have:

The trace is +1.7321, the determinant is 1.0, and there are no real valued solutions for eigenvalues. That tells us there are no (real valued) eigenvectors. However in the complex-valued world of quantum mechanics, there is an eigenvalue decomposition of the transforming matrix, but that’s a topic for another time.
Stay eigen, my friends! Go forth and spread beauty and light.
∇














March 1st, 2021 at 8:09 am
A useful equation for determining eigenvalues is:
Which defines the characteristic polynomial of matrix M.
It says that the determinant of matrix we get by subtracting λ×(Identity matrix) from matrix M is equal to zero. Since we know M and the Identity matrix, we can solve for values of λ that make the equality true.
As an example, consider the ScaleY matrix, which scales the Y-axis but preserves the X-axis. That matrix was:
Plugging that into the characteristic equation, we have:
Doing a bit of the math:
And then some more math:
Then using the definition of the determinant for a 2D matrix:
Which gives us:
And we can see that making the equality true requires:
QED! 😀
March 1st, 2021 at 12:14 pm
Of course, the next question is: Okay, we found the eigenvalues, but what about the eigenvectors? A useful equation for that is:
Since we now know the eigenvalues, λ1 and λ2, and of course we know M, we can plug in the values and solve the equality.
Let’s start with λ=1:
And since λ1=1, we have simply:
Doing the subtraction, we have:
And in this case it’s easy to see that:
For any value of x. As mentioned in the post, all vectors that lie on the X-axis are eigenvectors of the ScaleY(0.5) operator.
For the other eigenvalue, λ=0.5, we have:
Which is:
Or:
Which evaluates to:
And, again, it’s easy to see that:
For any value of y. So all vectors that lie on the Y-axis are also eigenvectors.
The characteristic eigenvectors would be the normalized vectors:
Once again, QED! 😀
March 1st, 2021 at 3:18 pm
How about another example. This time I’ll use the Scale(0.5) operator. The matrix for that operator is:
So we find the characteristic polynomial as:
Which is:
Doing the subtraction gives us:
Which means:
And obviously the only eigenvalue is λ=0.5.
So then we look for the eigenvectors with:
For λ=0.5 we have:
Which is:
Doing the subtraction leaves us with:
Which is the zero operator, so any vector, with any x and y, is (as stated in the post) an eigenvector for the Scale operator.
Still QED! 😉
March 1st, 2021 at 3:20 pm
(QED because these are simple examples. It isn’t always quite this easy.)
March 1st, 2021 at 6:27 pm
Just dropping in to note I’m still reading these. (Have to admit going into skim mode as the terms pile up.) Comprehension remains blurry and may fail completely at the end.
March 1st, 2021 at 7:23 pm
I’m afraid it’s not going to get better; we’re in very shallow water so far. If comprehension is blurry, this is the time to ask questions to improve the focus. Although, obviously it depends on how interested you really are — effort, not skimming, is what’s required here.
The take-away on this one basically is that, for some quantum system with possible observables (position, momentum, spin, energy, etc), there is an operator for each observable. These operators are represented as matrices, and they have eigenvectors and associated eigenvalues.
The eigenvectors of an observable are the kinds of measurements possible for that observable. The respective eigenvalues are the actual measurement values. The probability of getting a given measurement outcome is based on the inner product of the quantum state vector as the moment of measurement and the given eigenvector v:
After measurement, Ψ “collapses” to be the eigenvector that was actually observed.
The closer the current quantum state vector is to a given eigenvector, the higher the probability of getting that measurement. A consequence of this is that an immedate second measurement has the state vector in the eigenstate just measured, so the probability is 1 for that eigenstate and 0 for any others. If the eigenstate drifts away just slightly, the probability remains high of obtaining the same outcome, but is no longer exactly 1.
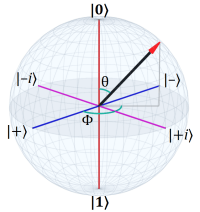
Spin measurements have only two eigenstates, “up” and “down”, and the associated eigenvalues are +h-bar/2 and -h-bar/2. Position measurements, on the other hand, have an eigenstate and eigenvalue for every possible position (in, like, the universe, which is why they say, in quantum mechanics there is some very small chance the particle can be anywhere).
March 1st, 2021 at 8:37 pm
Thanks for the additional explanation. So if I’m understanding, an eigenvector and an eigenvalue are essentially alternatives for the amplitude of a particular state vector? But the way I’ve seen “eigenstate” thrown around seemed to imply it’s the state vector itself. (If the confusion is utter and would require hundreds of words to explain, don’t worry about it. There’s a good chance it would just swish the confusion around. 🙂 )
March 1st, 2021 at 10:48 pm
I’ll try to keep it brief! 🙂
Quantum spin is physically mysterious, but mathematically one of the simpler parts of QM because it involves only two eigenstates (aka eigenvectors). An eigenstate is an observable property of a quantum system, and for spin, as I mentioned, the eigenstates are “up” (|0⟩) and “down” (|1⟩) for a measurement on some axis. We describe a system with unmeasured (and therefore unknown) spin as the superposition of those eigenstates:
Where α and β are the probability amplitudes of those eigenstates. The norm squared of those amplitudes is the probability of getting that outcome. Since a measurement results in a definite outcome, those probabilities must sum to 1.
If there’s an equal chance of either, it’s:
The norm squared of 1/sqrt(2) is 1/2, and 1/2 + 1/2 = 1.
The quantum state vector jumps to (“collapses” to) whichever eigenstate is the measurement outcome, so in that sense the quantum state vector is the eigenstate, at least until the system evolves to another superposition. The system can be kept in the eigenstate by repeating the measurement.
The eigenvalue is just the numerical value of the measured outcome. It obviously depends on what’s being measured.
A little over 200 words… hope it helps rather that swishes. 🙂
March 2nd, 2021 at 7:01 am
Thanks! That confirms my previous understanding. I’ll have to mull how it all fits together.
March 8th, 2021 at 12:01 pm
[…] and “spin-down” with two respective eigenvalues, plus and minus h-bar-over-two (see Eigen Whats? for more on […]
March 8th, 2021 at 7:32 pm
Let me give this a whirl–(bad pun as you shall see). Because there is an observable called spin, there is an operator for it. The operator is a complex matrix and because we can measure spin on X, Y or Z axes, there must be an eigenvector of the operator that corresponds to each. This is because there is an eigenvector for each of the different “properties” of the spin observable that we could measure. And then, the eigenvalues that go with this operator, for spin 1/2 particles, would be 1 or 0 (up or down, essentially in a Z-test).
There may be no physical correlates to the math, but just for the fun of it… we have this indeterminate “thing” and then we “operate” on it to find out what it is, and when we do the manner in which we operate on it only permits certain results (eigenvalues of a particular eigenvector). So the possible answers are predetermined by the question, in a sense, because the properties of the operator are independent of the “thing” we tried to examine.
Close?
March 8th, 2021 at 9:13 pm
Quite! (With some caveats.)
A spin measurement only has two possible outcomes (“up” or “down”) and, thus, only two eigenstates.
I think I’ll tackle this in more detail replying to your comment on the spin post. Here I’ll just mention that there are three spin operators, one for each axis. They are, indeed, matrices with complex values. As an example, the operator for the canonical Z-axis measurement is:
Which doesn’t contain complex values, but as you’ll see when I answer your spin questions, the matrix for the Y-axis does.
Your second paragraph is, as we used to say back in the day, “right on, man!”
In particular, yes, absolutely the outcomes are predetermined by the questions we choose to ask. As a simple example, we can ask about a particle’s position, which gives us one kind of answer (a location), or we can ask about its momentum, which gives us another kind of answer.
March 25th, 2021 at 1:50 pm
I meant to link to this video in the post but completely forgot. It’s a very nice overview of eigenvectors and eigenvalues:
I recommend the whole series, Essence of linear algebra.
It’s from one of the best (if not the best) math education YouTube channels, 3Blue1Brown. If one has any interest in math, it should be at the top of your list.
September 20th, 2023 at 2:29 pm
[…] on the left must also only scale the vector — so the vector has to be an eigenvector. [See QM 101: Eigen Whats? for more on […]