Monthly Archives: October 2015
 Last time we looked at the basic requirements for a software model of a computer and put a rough estimate on the size of such a model (about 2.5 terabytes). This time we’ll consider a software model of a human brain. Admittedly, there’s much we don’t know, and probably need for a decent model, but we can make some rough guesses as a reference point.
Last time we looked at the basic requirements for a software model of a computer and put a rough estimate on the size of such a model (about 2.5 terabytes). This time we’ll consider a software model of a human brain. Admittedly, there’s much we don’t know, and probably need for a decent model, but we can make some rough guesses as a reference point.
We’ll start with a few basic facts — number of neurons, number of synapses — and try to figure out some minimal requirements. The architecture of a viable software brain model is likely to be much more complicated. This is just a sketch, a Tinkertoy® or LEGO® version.
Even so, we’re gonna need a lot of memory!
Continue reading
10 Comments | tags: axon, computer model, dendrite, human brain, human connectome, human consciousness, human mind, long-term potentiation, LTP, neuron, petabyte, synapse, terabyte | posted in Computers
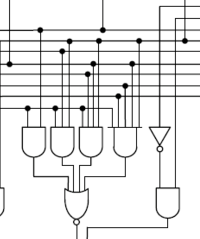 The computer what? Connectome. The computer’s wiring diagram. The road map of how all the parts are connected.
The computer what? Connectome. The computer’s wiring diagram. The road map of how all the parts are connected.
Okay, granted, the term, connectome, usually applies to the neural wiring of a biological organism’s brain, particularly to the human brain. But the whole point of this series of posts is to compare a human brain with a computer so that we can think about how we might implement a human mind with a computer. As such, “connectome” seems apropos.
Today we’ll try to figure out what’s involved in modeling one in software.
Continue reading
4 Comments | tags: computer model, connection map, connectome, human connectome, transistor, wiring diagram | posted in Computers
 The ultimate goal is a consideration of how to create a working model of the human mind using a computer. Since no one knows how to do that yet (or if it’s even possible to do), there’s a lot of guesswork involved, and our best result can only be a very rough estimate. Perhaps all we can really do is figure out some minimal requirements.
The ultimate goal is a consideration of how to create a working model of the human mind using a computer. Since no one knows how to do that yet (or if it’s even possible to do), there’s a lot of guesswork involved, and our best result can only be a very rough estimate. Perhaps all we can really do is figure out some minimal requirements.
Given the difficulty we’ll start with some simpler software models. In particular, we’ll look at (perhaps seeming oddity of) using a computer to model a computer (possibly even itself).
The goal today is to understand what a software model is and does.
Continue reading
4 Comments | tags: algorithm, American checkers, checkers, complexity, computer model, computer program, English draughts, Kolmogorov complexity, software, software model, state space | posted in Computers
 We started with mathematical expressions, abstract algorithms, and the idea of code — a list of instruction steps in some code language. We touched on how all algorithms have an abstract state diagram (a flowchart) representing them. Then we looked briefly at the stored-program physical machines that execute code.
We started with mathematical expressions, abstract algorithms, and the idea of code — a list of instruction steps in some code language. We touched on how all algorithms have an abstract state diagram (a flowchart) representing them. Then we looked briefly at the stored-program physical machines that execute code.
Before we go on to characterize the complexity of a computer, I want to take a look — very broadly — at how the computer operates overall. Specifically, look at another Yin-Yang pair: the computer’s operating system versus its applications.
This has a passing relevance to the computer’s complexity.
Continue reading
20 Comments | tags: algorithm, application code, computer program, hardware, O/S, operating system, software, stored program computer, system code, user code | posted in Computers
 When I was a high school kid, my dad and I sometimes played a game where one of us would make up a secret code, write a message in that code, and the other would try to decipher the message. We generally used simple substitution ciphers, so it was an exercise in letter frequency analysis and word guessing.
When I was a high school kid, my dad and I sometimes played a game where one of us would make up a secret code, write a message in that code, and the other would try to decipher the message. We generally used simple substitution ciphers, so it was an exercise in letter frequency analysis and word guessing.
There’s a cute secret code I found in a book back then that really stuck with me because of the neat way it looks. It also stuck with me because it’s so simple that once you learn it, you really can’t forget it.
So, for some Saturday fun, I thought I’d share it with you.
Continue reading
6 Comments | tags: Alan Turing, Alienese, cipher, code, decipher, decoder ring, Freemasons Cipher, Futurama, one-time pad, Pigpen Cipher, secret codes, substitution cipher | posted in Basics, Math
 We started with the idea of code — data consisting of instructions in a special language. Code can express an algorithm, a process consisting of instruction steps. That implies an engine that understands the code language and executes the steps in the code.
We started with the idea of code — data consisting of instructions in a special language. Code can express an algorithm, a process consisting of instruction steps. That implies an engine that understands the code language and executes the steps in the code.
Last time we started with Turing Machines, the abstract computers that describe algorithms, and ended with the concrete idea of modern digital computers using stored-programs and built on the Von Neumann architecture.
Today we look into that architecture a bit…
Continue reading
17 Comments | tags: address bus, algorithm, assembly language, bits, code, computer language, computer program, CPU, data, data bus, RAM, source code, stored program computer, Von Neumann architecture | posted in Computers
Long-time readers of this blog know I very rarely re-blog. Occasionally something strikes my fancy so hard, I have to (if nothing else) mention it and post a link to it here.
Derek Lowe, a chemist who also writes In the Pipeline, a great chemistry blog, recently posted something striking:
…a new analysis of clinical trials for pain medication shows that the placebo effect in [the area of pain relief] has been getting stronger. The same also seems to be true for antipsychotics and antidepressants, but this effect seems to be mainly (or only) visible in large-scale US trials…
Continue reading
1 Comment | tags: belief, chemistry, Derek Lowe, drug trials, In The Pipeline, medical trials, pain relief, placebo, power of will, USA | posted in From My Collection, Science

Is that you, HAL?
Last time, in Calculated Math, I described how information — data — can have special characteristics that allow it to be interpreted as code, as instructions in some special language known to some “engine” that executes — runs — the code.
In some cases, the code language has characteristics that make it Turing Complete (TC). One cornerstone of computer science is the Church-Turing thesis, which says that all TC languages are equivalent. What one can do, so can all the others.
That is where we pick up this time…
Continue reading
2 Comments | tags: Alan Turing, algorithm, Church-Turing thesis, code, data, flowchart, lambda calculus, state diagram, stored program computer, Turing Machine, Universal Turing Machine, Von Neumann architecture | posted in Math
 The previous post, Halt! (or not), described the Turing Halting Problem, a fundamental limit on what computers can do, on what can be calculated by a program. Kurt Gödel showed that a very similar limit exists for any (sufficiently powerful) mathematical system.
The previous post, Halt! (or not), described the Turing Halting Problem, a fundamental limit on what computers can do, on what can be calculated by a program. Kurt Gödel showed that a very similar limit exists for any (sufficiently powerful) mathematical system.
This raises some obvious questions: What is calculation, exactly? What do we mean when we talk about a program or algorithm? (And how does all of this connect with the world of mathematics?)
Today we’re going to start exploring that.
Continue reading
13 Comments | tags: Alan Turing, algorithm, binary digits, calculation, Church-Turing thesis, code, computer program, data, information theory, lambda calculus, mathematical expression, Turing Machine, Universal Turing Machine | posted in Math, Opinion

evaluate(2B || !2B)
Hamlet’s famous question, “To be or not to be?” is just one example of a question with a yes/no answer. It’s different from a question such as, “What’s your favorite color?” or, “How was your day?” What it boils down to is that the young Prince’s question requires only one bit to answer, and that bit is either yea or nay.
Computers can be very good at answering yes/no questions. We can write a computer program to compare two numbers and tell us — yea or nay — if the first one is bigger than the second one. Computers are also very good at calculations (they’re just big calculators, after all). For example, we can write a computer program that divides one number by another.
But there are questions computers can’t answer, and calculations they can’t make.
Continue reading
11 Comments | tags: Alan Turing, algorithm, calculation, Cantor's Diagonal, discrete mathematics, Halting Problem, Turing, Turing Halting Problem | posted in Computers, Sideband













