 Entropy is a big topic, both in science and in the popular gestalt. I wrote about it in one of my very first blog posts here, back in 2011. I’ve written about it a number of other times since. Yet, despite mentioning it in posts and comments, I’ve never laid out the CD collection analogy from that 2011 post in full detail.
Entropy is a big topic, both in science and in the popular gestalt. I wrote about it in one of my very first blog posts here, back in 2011. I’ve written about it a number of other times since. Yet, despite mentioning it in posts and comments, I’ve never laid out the CD collection analogy from that 2011 post in full detail.
Recent discussions suggest I should. When I mentioned entropy in a post most recently, I made the observation that its definition has itself suffered entropy. It has become more diffuse. There are many views of what entropy means, and some, I feel, get away from the fundamentals.
The CD collection analogy, though, focuses on only the fundamentals.
In fact, those who already have a defining view of entropy can find it confusing because it’s such a simplified abstraction. Hopefully it works better for those unfamiliar with the concept — they (you? hello!) are the intended audience.
The CD collection analogy has two goals: It seeks to illustrate the formula Boltzmann devised for quantifying entropy. It also seeks to explain why entropy is often explained as “disorder.” Some disdain disorder as a description, but I think seen through analogies like this it makes more sense.
§ §
I’ll start by quoting myself from a post last year:
Entropy defines differently depending on the domain. In communications (information theory), it focuses on errors in data. In computer science, it can refer to randomness for cryptography.
Those are specialized views. The most general English-based definition is that entropy is a measure of disorder. This definition is so general it drives most physicists a little crazy (because: define “disorder” … and “measure”).
A more precise English-based definition is more opaque: Entropy is the number of indistinguishable micro-states consistent with the observed macro-states.
That last one is the (non-mathematical) definition. It’s the most accurate and fundamental way to state what entropy is as expressed in Boltzmann’s formula:

Where S is the entropy, K is a constant (Boltzmann’s constant), and Ω (Omega) is the number of micro-states grouped as “indistinguishable” under some set of (view-defined) macro-states.
This obviously requires both explaining and applying to examples. (Analogies such as the CD collection try to do the former.)
§
Everything centers on the dual notions of macro-states and micro-states. In Boltzmann’s formula, the latter is explicit in the quantity Omega. The former is implicit in a given value of Omega.
From that same post:
A macro-state is a property we can measure in a system. A macro-state is an overall property of the whole system, such as its temperature, pressure, or color. In the example of the CD collection, how well it’s sorted is a property of the whole collection.
A micro-state is a property of a piece of the system — usually, as the name implies, a small, even tiny, piece. The molecules of a gas or liquid all have individual properties, such as location and energy…
We say that micro-states are indistinguishable when different arrangements of micro-states have no effect on a given macro-state.
The micro-states of a system are usually obvious. They’re the smallest meaningful building blocks comprising the system. The granularity depends on the system. A quantum system has quantum micro-states, but in a gas system the micro-states involve gas molecules. (In information systems, the micro-states involve bits.)
The macro-states are not obvious, in part because they depend on what properties of the overall system interest us. The gas system has temperature and pressure macro-states as well as macro states involving the arrangements of its molecules. Macro-states depend on how we choose to view the system as a whole.
Macro-states are also complicated because of partitioning. Many systems are continuous, so their behavior at a macro-level must be partitioned into groups. For instance, temperature is measured in degrees (or down to some fractions of degrees), but that temperature number includes all the temperatures closer to that number than the next. So how we partition macro-states affects Omega.
However, given we’ve finally defined the macro-state, Omega is the number of permutations of the micro-states that result in that same macro-state. The entropy behavior (or curve) of a given system is the set of Omega values for all its macro-states. In real systems, Omega easily becomes astronomically astronomical (hence using the log of Omega to tame it a bit).
For instance, the vast number of possible arrangements of air molecules in a room that result in the same temperature or pressure. That number is the factorial of number of molecules. It’s big beyond our sensibility.
§ §
With those definitions and observations, let’s get to the CD collection analogy. The name announces the basic image: a collection of CDs. We’ll imagine it’s a very large collection — at least 5,000.
A key point here is that the CD collection is a concrete image of the abstract idea of an ordered set. Brian Greene uses the pages of the novel War and Peace to illustrate the same thing in his book The Fabric of the Cosmos. A box of index cards with serial numbers on them is another example. So is a library of books sorted by Dewey Decimal number.
In all cases, we care about two things: That each member of the collection has a property that uniquely identifies it. And that property must allow the collection to be perfectly sorted. (In essence, it is always true that either a<b or a>b.) Our entropy abstraction can use any collection with such a property.
Crucially, exactly how the CD collection is ordered doesn’t matter. It could be date purchased; order added to collection; ISBN number; or some code number we randomly assign. A more natural order might be by Artist, Release Date, and Title, but it could be anything. All that matters is that we have a definition that allows a perfect sort.
§
I said the micro-states of a system are obvious, and here — in the context of a sorted collection — they’re obviously the positions of each CD. The information in micro-states generally comprises a full description of the system. In the context of an ordered collection, the positions of each CD do comprise a full description of the collection.
The macro-states are a more complicated proposition, and it turns out that’s true on at least two levels. Firstly, for all the usual reasons, but here also for a reason I hadn’t anticipated.
I’ll refine this more as we go, but to start with a casual definition, the macro-state of the collection is “how sorted” the collection is. This, as with temperature and pressure, is a single value expressing an overall property of the system. It seems, however, four+ decades of computer science blinded me to a “how sorted” property being a foreign idea outside that realm.
I’ll unpack it below, but for now take it on faith the CD collection has a “how sorted” property — a single number that quantifies the degree to which the collection is sorted. We’ll call this the sort degree. For now, assume it exists and is our macro-state. Imagine we have a device that, as does a thermometer or pressure gauge, sums over the collection and returns a single number: temperature, pressure, or “how sorted.”
§
Given this (for now magical) macro-state, we can calculate Omega and, thus, the entropy of a given macro-state. Natural systems are extremely challenging, but the CD collection gives us some chance at actual quantification.
We can, for instance, easily quantify the zero-entropy state. Natural systems can’t have zero entropy, but abstractions can, and it makes a good first illustration of Boltzmann’s formula.

There is only one arrangement (permutation) of the CD collection that is perfectly sorted, and log(1)=0. We’ll define the sort degree here as zero, too, but don’t confuse sort degree with entropy. They just happen to both be zero in this case.
In fact, there are three numbers to keep straight: The sort degree, which is a macro-state quantifying “how sorted” the collection is; Omega, which is the number of micro-states matching a given sort degree; and the entropy, which is the log of Omega times a constant.
The next sort degree after zero is one, which means one CD out of place. In fact, the sort degree is defined as the minimum number of moves required to restore the collection to perfectly sorted. This usually tracks the number of CDs out of place.
The number of permutations with one CD out of place is: N×(N-1), where N is the number of CDs (because each of N CDs can misplaced in N-1 places).
If we have 5,000 CDs:
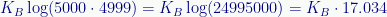
And that is just the first jump in entropy after zero. The numbers get much bigger as more and more CDs are out of order and the number of permutations rises.
Since Boltzmann’s constant is a constant, I’ll ignore it from now on (it just brings the actual value we get into better synch with thermodynamics). I’ll also mention here that we’re using the natural log function, not the base-10 or base-2 log.
§
Let’s get back to the question of macro-states and the “how sorted” property. One possibility is constructing the macro-states based on permutations. Unfortunately, that approach results in duplicates, confusion, and the end of the universe.
Consider a simple example given the ordered collection [ABCDEF]. Is the permutation [CDEFAB] four items out of place (CDEF) or two (AB)? Naively generating permutations based on X-many CDs misplaced results in patterns that should belong to other macro-states.
We could mitigate the problem by filtering out permutations that occur in lower sort degrees, but there’s a small problem. Or, rather, a big one. A really big one. The total number of permutations is N! — the factorial of N. For 5,000 CDs, that number has 16,326 digits. (It starts off: 4228577926…) There isn’t enough memory in the universe to store the permutations.
The punchline here is that it’s an NP-hard problem (read: currently effectively impossible) to accurately calculate sort degree from a random permutation. The “accurately” is important. It’s always possible to come up with a sort degree by just sorting the permutation and counting the moves, but it’s NP-hard to find the minimum one.
For our abstraction we declare a magic measuring “thermometer” that scans the collection and returns that accurate (minimum) sort degree.
§
There are ways to track the sort degree over time, but that gets into indexes, which I think is worth a separate post. There is also the matter of how the CD collection evolves — what makes its entropy go up or down.
All that and more next time.
§ §
Note that I haven’t so far said a single word about energy or work. That’s because entropy is a more abstract concept than its application in thermodynamics (even though it sprang from there). Physical systems using energy and doing work are applications for which entropy can be a useful measure (or at least a useful concept).
Stay entropic, my friends! Go forth and spread beauty and light.
∇













November 27th, 2021 at 10:10 am
Hello Wyrd,
I have one item in which me may not be aligned that would be interesting to discuss.
I think the definition of a microstate you gave is not quite correct for every form of entropy commonly discussed. You wrote, A micro-state is a property of a piece of the system — usually, as the name implies, a small, even tiny, piece. The molecules of a gas or liquid all have individual properties, such as location and energy…
We say that micro-states are indistinguishable when different arrangements of micro-states have no effect on a given macro-state.
In the classical thermodynamic example of a gas in a chamber with a temperature, where different particles can have different speeds and locations, the individual particles each have “properties” like position and velocity, but these are not micro-states of the system. A micro-state of the system being studied is the instantaneous configuration of all particles in the system. The micro-state in thermodynamics, in other words, is not the property of any particular particle or subset of particles, but one state (or configuration) of the overall system, consisting of all particles and their positions and velocities, amongst the many such states (or configurations) that are possible, that return the same temperature.
In information theory, I don’t have a good grasp on this, but it seems Shannon Entropy is something like the quantity of information in a variable, or alternately (equivalently I gather) when expressed in the form similar to the Boltzmann entropy, the entropy of a “variable” is related to the log of all possible “values” it can have. So in this case, for information theory, the macro-state would be the variable studied (“what kind of tea are you having?”), and the micro-states would be each of the various possible values (black, green, mint, rooibos, chamomile, etc.). In this case, however, I am under the impression the micro-state still involves the totality of the variable’s content.
For example, if it takes eight bits to describe all possible values of a variable X, then the micro-states are all the possible (by which I mean, if the variable is “which tea” then the string “Mickey Mouse” even if it were possible to construct from the bits available, would not be considered) coincident values of those eight bits. Now, not all combinations of those bits may represent plausible states, so in this sense “they are not possible” and would be excluded from the entropy calculation as I understand it. (The Mickey Mouse tea case.)
This is fun to think about because I don’t understand it fully, and at the same time it seems significant… At any rate, my only point here is that I don’t think micro-states are subsets of the systems being studied. They are at least in some cases, possible configurations involving all the elements of the system, whether they are particles of gas in a sealed chamber or characters in a string that comprise a signal.
Michael
November 27th, 2021 at 2:07 pm
“You wrote, A micro-state is a property of a piece of the system “
That’s me quoting my post from last June, and the wording could have been better. I hope it’s clear from context that, yes, a micro-state involves all the particles. It can be hard keeping the plurals straight sometimes. A micro-state versus the micro-states of the system.
“A micro-state of the system being studied is the instantaneous configuration of all particles in the system.”
Absolutely. Again, I hope this is clear from the overall context of the post, such as when I discuss the micro-state of the collection being the positions of all the CDs.
As I mentioned before, I’m not read up on information theory enough to discuss it competently. I’ve never gotten the sense that it applies to multiple tea answers to “which tea” question, but the ability of understanding a message about tea. True, sufficient distortion of the message could result in a undistorted other message, but that would seem like a system moving to a low-entropy state. Usually the movement is towards disorder — a corrupted message.
I do understand that, yes, in that message the bits are the micro-states. A zero-entropy message would be one in which all bits are correct as intended. (Because of the error correction that goes on, especially over the internet, most users aren’t aware that these systems aren’t zero entropy. Bit errors occur frequently.)
November 27th, 2021 at 3:16 pm
Your series has inspired me to snoop around a bit on Shannon entropy, Wyrd. Most of my background with entropy is from the thermodynamic vantage, and so it’s been interesting. I don’t claim any particular understanding and admittedly you don’t either, so perhaps it’s the blind leading the blind. But in the spirit of trying to restate what I think I’ve learned, I wanted to respond to these two statements you made:
I’ve never gotten the sense that it applies to multiple tea answers to “which tea” question, but the ability of understanding a message about tea.
And
A zero-entropy message would be one in which all bits are correct as intended.
I think it will make sense if we start with the second statement. As I understand it Shannon’s definition of entropy relates to both a) the amount of surprise a message may contain and b) the minimum quantity of information required to encode the message (e.g. the lowest quantity of information, in bits, required to convey the message, which is different than the number of characters in the English language for instance).
The only case where a message would have zero entropy is if the possibility of surprise is zero. So, for instance, if you only possessed a single stamp and it said “green,” and that’s the only way you could communicate, then when I asked what type of tea you were having, the answer would be green. If I asked you what type of car you drive, the answer would be “green.” So there’s no ambiguity in your replies, the probability of the answer being green is 1, and there is no possibility of surprise. And at the same time, the number of bits required to convey a single response—a message with a probability of 1—is nearly zero. (I’m not sure if it is zero or 1 . . . probably 1, and then the log of 1 would be zero, for zero entropy.)
The longer the message, the more bits required to convey it, the more information it contains, and the greater the possibility for surprise as compared to a random distribution. So long messages innately have higher entropy. I think what I’ve learned is that this relates to the thermodynamic version of entropy in the sense that micro-states of high entropy thermodynamic states require a lot more information to define than the micro-states of low entropy macro-states. Similarly, long messages may contain a lot more information than short (low entropy) ones, or to say it another way, long messages (high entropy) require a lot more information to convey. The space of possible micro-states is much larger for longer messages because a lot more bits are required to convey the message.
I should stop there, but just to circle back to the first quote about tea: if I ask you what type of tea you’re drinking, then presuming you are answering the question and not just randomly shooting bits down the wire, there is a minimum number of bits in the message you give back that will specify the answer. (That quantity is based on all possible answers and their probabilities of being the right one.) The greater the number of possible answers, the greater the number of bits required, and the higher the entropy of the message you send.
November 27th, 2021 at 6:47 pm
With the caveat this is fairly unexplored territory for us both…
To some extent, I think your (a) and (b) are the same. The potential amount of “surprise” a message can have is directly related to how many bits it contains. As you point out, with a single bit. Looking at the Entropy (information theory) Wiki page, I think it’s calculated:
But I make no guarantees.
I did notice the intro says: “When the entropy is zero bits, this is sometimes referred to as unity, where there is no uncertainty at all – no freedom of choice – no information” So, I have the sense entropy here refers to a potential for error. Certainly the longer the message, the greater that potential has to be.
“So long messages innately have higher entropy.”
That does seem to be what it boils down to, and that may be why I’m bothered a bit by calling this entropy (rather than potential error or something that wouldn’t confuse people into making comparisons with thermodynamics).
I think where the tea analogy broke down for me was that I can see where bit errors can corrupt the message into something confusing, I don’t see much likelihood of bit errors causing an apparently clear different tea message. I think maybe what you’re conveying, though, is that any answer I could get would be some kind of tea. Are you positing a situation where, say, the answer is four bits, and all patterns of four bits convey a reasonable type of tea? In that case, yes, totally!
November 28th, 2021 at 5:22 pm
I think your emphasis on error in Shannon entropy could be (not 100% sure) a holdover from the precepts of thermodynamic entropy, and not the crux of the issue in information theory. Not to say the notion of messages being degraded through multiple cycles of encoding, transmission, and decoding doesn’t make sense, because it does. But it seems the core definition of entropy in information theory is not to do with error, but information content. (And I agree calling it entropy can be confusing when we think about other forms of entropy.)
It’s also possible that what I’ve been reading is the idealized case, or the starting off point, and that in Shannon’s more advanced work regarding noisy transmissions (as opposed to noiseless), error plays a much larger role. That would make some sense. But I don’t know.
At any rate, to return to the tea analogy, the answer to your question is yes. As I understand it, if the variable being studied is the answer to the question, “what tea are you drinking?” then it is presumed the space of possible answers is an exhaustive list of teas. And that’s it. This is no different than in quantum mechanics when we have a wave function. If we ask about the position of a particle, “bicycles” and “red” and “perestroika” are not included in the set of possible answers.
The question of Shannon entropy and information theory appears to be one of determining the minimum number of bits required to uniquely deliver each possible answer. And the larger the space of possible answers, the higher the entropy assigned to the message that describes the variable in question.
November 29th, 2021 at 10:17 am
My impression of Shannon entropy comes from computer science and data transmission work (in an earlier life I serviced fax machines and telecommunications terminals). It has never been a topic I’ve dug into (because it’s huge and very mathematical), but my sense of it comes from data transmission and compression work. Error and information content are directly linked, especially if data compression is involved. My understanding (FWIW) is that Shannon’s work arose from data transmission and compression needs.
The thing to be clear about in the tea analogy is that, we’re apparently talking about a four-bit pattern where every possible bit pattern maps to a valid answer, a type of tea. So, any bit error(s) convert the original answer to a perfectly valid different answer. What confused me is that isn’t how data transmission usually works. Errors tend to corrupt a message, not convert it to a perfectly valid different one. If we imagine additional parity or error-detection bits (which nearly all forms of transmission use), then bit error(s) would be detected as corruption.
November 29th, 2021 at 9:26 pm
I think everything here is generally correct when it comes to information theory as a whole. But perhaps as was the case with your CD analogy and my tendency to run ahead into other thermodynamic considerations, I think that is happening here with the example of applying the concept of entropy in information theory to the answering of a question, you’re getting into other aspects of information theory that are going beyond the simplest/baseline definition of entropy.
In the theoretical sense, entropy in information theory is defined as the minimum quantity of information necessary to convey the possible values for a given variable. You wrote What confused me is that isn’t how data transmission usually works. Errors tend to corrupt a message, not convert it to a perfectly valid different one.
A message that only contains the quantity of bits described by the entropy function is lossless. As you note, this doesn’t happen in reality. I think there’s a lot of additional considerations in information theory. But perhaps its helpful to take this example slightly further. Imagine a question or variable whose possible values, based on a Shannon entropy analysis, requires 27 bits to convey. But in a binary system, we can’t have only 27 bits. We’ve got to work with 32. So some possible values will be junk.
(I think also it may only take five bits to code 32 values, so I said it slightly wrong, but I definitely don’t think this way very often. Haha. The point is that with inflexible hardware, if we can’t optimize the base counting system, and we’re only working with binary, then that alone may prevent us from sending messages with the theoretical minimum number of bits.)
November 30th, 2021 at 9:17 am
I think we might need to distinguish between information theory and Shannon entropy. The latter being a subset of the former. My view of the latter does include notions like his noisy-channel coding theory. No doubt that’s where I picked up the sense that it’s mainly about data transmission and compression. And from text like this:
From the Wiki article on Shannon entropy.
Determining how many bits are required to just express a value is pretty simple. It’s just log2(N) where N is size of the answer space. As an example, if my variable will contain just uppercase English alphabet characters, of which there are 26, we have log2(26)=4.7 (and change). Call it five bits, which give us 2^5=32 possible answers. We can’t send 0.7 of a bit, so we’re stuck with our five bits having 32-26=6 garbage characters. Unless we assign meaningful value, such as mapping them to other characters (e.g. space, newline, etc). As that Wiki article starts: “In information theory, the entropy of a random variable is the average level of ‘information’, ‘surprise’, or ‘uncertainty’ inherent in the variable’s possible outcomes.” And the ability to surprise definitely is connected with how many bits are involved, but I can’t shake the sense that it’s more than just that. (Fully understanding that might just be a bone I can’t let go of yet. Sometimes one gets an idea in their head they have a hard time shaking.)
Meanwhile, I was trying to figure out why my math didn’t seem to match. I got the result 0.5, but the article says it should be 1.0 bits of entropy. Re-reading it, I see the formula doesn’t iterate over the probabilities of the bits, but the probabilities of outcomes. I had one bit with an assumed probability of 0.5, but the sum should be over two possible outcomes (0 and 1), each with 0.5 probability. That does give the correct answer.
(BTW: I got confused in your last paragraph. Where did five bits (which indeed have 32 possible values) come into the picture? You went from 27 bits fitting into 32 bits, and then jumped to 5 bits and 32 values? Were you referencing the tea thing maybe? I couldn’t connect it to the penultimate paragraph.)
As an aside, back in the comments for that Friday Notes post, Mike (Smith) mentioned how Brian Greene had an analogy for (thermodynamic) entropy that used the unbound pages of War and Peace. Turns out I have the book that’s in (The Fabric of the Cosmos), and last night I got around to re-reading that part of the book. He and I are saying exactly the same thing, which makes me feel a lot better about my CD collection. (It’s quite possible reading this years ago is part of my view.) At one point Greene writes, “The example of War and Peace highlights two essential features of entropy. First, entropy is a measure of the amount of disorder in a physical system.” The second feature, which he doesn’t get to for several paragraphs, is that entropy overwhelming statistically increases in isolated physical systems. At least my understanding of thermodynamic entropy seems okay! 🙂
November 30th, 2021 at 6:48 pm
I’ve enjoyed this, Wyrd. But have definitely exhausted my knowledge.
You’re confused about my bits vs values example because I was confused. I realized too late that the number of values I could convey was different than the number of bits because as you noted five bits give 32 possible values. I came to this conclusion myself in the middle of my thought experiment, and I tried to clarify instead of starting over, so apologies for the confusion. What I was trying to say was exactly what you surmised, if there were 27 types of tea–27 values for the variable in question–then there would be a few junk values if we had to convey that information in a binary system with 5 bits.
On Shannon entropy, I do think you have the bone between your teeth. You’re absolutely right Shannon entropy is just one piece of information theory. My take is you are trying to put more into the explicit definition of Shannon entropy than is there, while your intuitions about the theory as a whole are spot on. It’s not worth saying the same things over again, though, so we just leave it at that for now I say!
December 1st, 2021 at 7:56 am
Heh, I know the feeling!
No doubt my sense of Shannon entropy comes from knowing about Shannon’s early work that led to it, but also from something I’ve been meaning, but keep forgetting, to include in this discussion: cryptography (which is also a subset of info theory). When talking about encryption and encryption keys, entropy definitely refers to the variable’s content. Its length is a factor, but its bit content is what matters. An encryption key needs maximum entropy — randomness in the bit pattern — to have value. The encryption itself needs apparent maximum entropy — the cyphertext must appear to be random to have value.
It’s similar to a ZIP file. Compressed data approaches the limit of the amount of information a given number of bits can contain (which is why you can’t ZIP a ZIP file and gain anything; you usually end up with a larger file). ZIP files have high apparent entropy — without their dictionary, they appear random.
I’m sure those contribute to my overall sense of Shannon’s entropy, although the math, as you’ve said, deals just with the number of possible messages and, hence, variable length.
Great discussion! I’ve enjoyed it a lot, thank you!!
December 12th, 2021 at 10:57 am
Unless you’re getting reply notifications or circle back around some day, you may never see this, but FWIW I got into Shannon entropy a little (see comment below and in next post). In doing so I might have stumbled over an apparent point of disconnect. Which might not be a disconnect at all.
Using the tea example, the entropy of a variable that could contain any of the 27 answers is indeed 4.754 (and change). If there were 32 possible answers, the entropy of a five-bit variable having any of those 32 answers would be 5.0. (In encryption you want your variables to have that highest possible entropy. An encryption key must contain any possible value with equal probability. It must be maximally unguessable.) A key point is that, under this view, there is only one entropy value for a given number of possible values.
But looking at the 27-answer tea situation in the context of an expected answer provides an alternate view. Here the emphasis is on transmitting or storing a variable and then accurately (or not) receiving or retrieving it. It’s not to say we necessarily know the expected value, but the view here assumes there is one and, more importantly, the probability of the expected value is different from values with bit errors. Under this view, the entropy of the system changes depending on those probabilities. For example, in the five-bit case, if the odds of a single bit error are 1/100 (and they multiply, so the odds of a two-bit error are 1/10000 and so on), then the odds of the expected answer are just over 95% and the entropy is down to 0.4 (and change).
So I think ultimately we were just looking at the same thing from two points of view.
December 16th, 2021 at 6:33 pm
Thanks for the direct note, Wyrd! Yes, I’ve been following along as best I can. Work has had me on the road, and long days have slowed me down a bit on keeping up. I understand what you’ve been doing (generally) and because of my lack of expertise in information theory, can only say it all makes sense.
Here is one point that comes to mind:
1. Shannon entropy for a given variable can vary based on the probabilities assigned to possible values that variable can be assigned. In my 27-answer tea model, if you know I generally drink green, with maybe peppermint and chamomile on the odd occasion, you could assign probabilities in such a way that the entropy of the signal containing the information about what tea I’m drinking would be reduced. This is the case without any consideration of noise.
2. Then you can add in the part about bit errors, which in a sense is a separate consideration. I still don’t know if this is how it is applied in the field or not. I understand how you applied the mathematics when considering bit errors, and I agree completely errors occur in real life, I just don’t know if consideration of those errors is what the formula we’re referencing for Shannon Entropy is applied to generally. And my only hesitation here is that the various articles I read when we were into this is that the entropy is independent of the type of system used. For instance, a message could be conveyed on paper using symbols, or in a system that isn’t restricted to binary formulations. We could use base three mathematics for instance, if we were sending bits on paper, and that would allow us to cover the 27-answer tea scenario with just three values (three bits in a sense, if you’ll permit a bit with 0, 1 or 2 as possible values).
How this one formula does all these things is what I’m unclear about? I think your note above where you said we need to distinguish between the basic definition of Shannon Entropy and Information Theory as an overall field still comes into play…
December 17th, 2021 at 4:13 am
Sorry I’m slow responding. After months of mostly trouble-free operation, that WiFi problem I had got much worse, and then the laptop began acting weird, and then it died, won’t even boot. I’ve spent all evening setting up the new HP laptop I bought (and I have a lot yet to do). But at least I have a reliable PC again!
Anyway, answering your numbered questions:
1. Yes, absolutely. The entropy of a given variable depends on the probabilities of its possible values. There’s no “can” about it; that’s exactly what the formula says.
2. Looking at it in terms of bit errors is just another view of the same thing. Same formula, different POV. We are in both cases system independent. We can talk about bits because a fundamental axiom of information theory is that all information reduces to bits. Looking at it in terms of higher symbol densities just changes the numbers a bit.
That’s the short answer. Here comes the long one…
The first case is essentially the cryptography view. Here we look at a variable just in terms of its maximum entropy (and don’t consider bit errors). This is the view that links entropy with “surprise” — higher entropy means higher surprise. Maximum surprise (maximum entropy) is when the variable could have any value with equal probability. This amounts to each bit being random. We want encryption keys to be 100% random this way — they should have maximum entropy, maximum surprise.
In the case of your 27-answer tea question, let’s treat that answer as an encryption key. If we assign equal probability to all 27 answers, the entropy (surprise) is maximum. I would have only a 1/27 chance (3.7%) of guessing it. The entropy in such a case is:
Which evaluates to 4.7548875… That it’s almost 5 is no coincidence. As you noted, it takes five bits to express 27 values, but that leaves 5 values unused. That the answer is in bits due to using log2. We can use other bases. If we use log10 we get 1.43136… — less than one-and-a-half decimal digits to express 27 values. Of course, log2(32)=5.000 and log10(100)=2.000. The actual entropy value isn’t about any system, but the number of symbols needed (for a given symbol density).
Now if we use log27, the answer is 1.000, because we’re assuming the variable is a single thing, such as a piece of paper or other single token with 27 values. The maximum entropy of any single symbol in terms of that symbol would always just be 1.000. OTOH, if we used trinary (three values), then the answer is 3.000, because three “trits” can express exactly 27 values (from 000 to 222). (Note that, if we wanted to use the 26 letters, log26, we get 1.01158… because 26 letters is almost enough for a single character, but one tea would be left over.)
These max entropy values assume equal probability (max surprise) for all possible answers. As mentioned, it’s required in encryption keys, and encrypted text should appear to have maximum entropy. If it doesn’t, it may be crackable. If we assign different probabilities to various answers, entropy (surprise) drops. In the extreme case, if I’m 100% certain of your answer, I effectively already know it, so no information is exchanged, and entropy is zero.
Let’s say you’re most likely to drink green tea, but there’s a 50/50 chance you’ll pick oolong, mint, or rose hip. There’s a 1/10 chance you’ll pick one of the other 23 teas. Note that these nominal odds need normalizing, because the total odds of all 27 must sum to 1.00. We start by assuming 100% odds for green, 50% odds each for oolong, mint, and rose, and 10% odds each on the 23 remaining. That gives us total odds of 1.0+(3*0.5)+(23*0.1)=4.8, our normalizing factor. We end up with normalized odds of 0.208, 0.104, 0.021, respectively, for the three groups.
So, it’s 21+% chance of green; 10+% chance of oolong, mint, or rose hip. That’s 51+% so far, the remaining 48+% is split evenly among the other 23 teas (2.1% each). The entropy in this case is still on the high side, 4.1673…, but is lower than random. I obviously have better odds of guessing your tea password.
If we say there’s only a 25% chance of one of the alternate three, and only a 1% chance of the remaining 23, the normalized probability of green is 50%, and the entropy is down to 2.515… bits. I have very good odds of guessing your password now!
One more jump: 20% for the three alternates and 0.01% for the other 23 (you really don’t like them, but on some rare occasion you might pick one). Now green tea is 62+%, and entropy is down to 1.57… (I’ll mention again that the only reason the answers are in bits is because we’re using the log2 function. Other log bases would give us answers in digits, trits, alphas, or whatever.)
Bit errors obviously aren’t a factor in these determinations. The maximum entropy a given number of symbols can have assumes bit fidelity. Bit errors connect to this in their ability to smear an expected answer (the sent answer). They mimic the effect of the possibility of choosing one of the other teas. Bit errors turn one message into another message, but there is a presumption of “closeness” — a single bit error results in a “close” message analogous to the oolong, mint, and rose hip teas. They’re “close” to green; the other teas are less close with more bit errors. A striking difference is that the tea example has only three macro-states (green, oolong/mint/rose hip, others) but bit error macro-states are as many as there are bits.
As a final weedy comment, it’s easy to assign a list of probabilities for 27 teas. It’s even easier to group them into those three macro-states and provide only three probabilities. Things get more interesting with bit error macro-states. I commented in the next post about the distribution and calculation, so I’ll just point you there for details. Suffice here to say, first you have to determine the population distribution, then calculate the normalized probabilities from some scheme, and finally provide a way to map a given bit pattern to a macro-state and its normalized probability. It turned out to be kind of a fun small Python project. 🙂
December 17th, 2021 at 10:07 am
I don’t know if you use Python, but if you do, here’s some code you can play with:
002|
003| def calc_entropy_1 (probs):
004| """Calculate Tea Entropy.
004|
004| Assumes 27 types of tea in 3 macro-states:
004| A – one tea type
004| B – three tea types
004| C – remaining 23 tea types
004|
004| Takes list of three relative probabilities
004| to apply to macro-states A, B, and C.
004| """
005| n_patterns = 27
006| # Macro-state population sizes…
007| sizes = [1, 3, 23]
008| # Total (relative) probability…
009| tots = [n*p for n,p in zip(sizes,probs)]
010| tprob = sum(tots)
011| # Normalized probability factors…
012| pfs = [p/tprob for p in probs]
013| # Define a Probability Function…
014| def PF (x):
015| if x == 0: return pfs[0]
016| if x in [1,2,3]: return pfs[1]
017| return pfs[2]
018| # Probabilities for each tea type…
019| ps = [PF(p) for p in range(n_patterns)]
020| # Individual entropies for tea types…
021| ents = [p*log(p,2) for p in ps]
022| # Results…
023| ent = –sum(ents)
024| print(‘%.8f (%.6f)’ % (ent,sum(ps)))
025| print(pfs)
026| print(‘%s %s’ % (tots, tprob))
027| print()
028| return ent
029|
030| def calc_entropy_2 (logbase=2, NP=27):
031| """Calculate Shannon Entropy."""
032| # Generate probabilities…
033| ps = [1.0/float(NP) for p in range(NP)]
034| # Generate entropy…
035| es = [(p*log(p,logbase)) for p in ps]
036| ent = –sum(es)
037| # Print (and return) result…
038| print(ent)
039| print(sum(ps))
040| print()
041| return ent
042|
043| def demo1 ():
044| """Calculate different probability lists."""
045| calc_entropy_1([1.0, 1.00, 1.0000])
046| calc_entropy_1([1.0, 0.50, 0.1000])
047| calc_entropy_1([1.0, 0.25, 0.0100])
048| calc_entropy_1([1.0, 0.10, 0.0001])
049|
050| def demo2 (logbase):
051| """Calculate different log bases."""
052| return calc_entropy_2(logbase=logbase)
053|
(I used the second function to mess around with different log bases.)
December 21st, 2021 at 12:48 pm
Updated this with some code tweaks and a better syntax color scheme.
December 30th, 2021 at 8:42 am
I’m getting the feeling you’re not coming back? (I was curious whether I’d answered the questions you posed…)
December 30th, 2021 at 9:19 am
Yes I’m good for the present. I understand what you shared. (I don’t use Python, but understood the first note with the discussion of how different bases affect the numerical result.)
I’m still a bit stuck on how the one basic formula gets used two different ways, meaning the variables mean different things depending on the point of view, but it’s still all called Shannon entropy. I find that confusing. But we’ve gone around enough on that and I’m good with where we are. I’m not worried about it honestly and think if I want to understand better I’ll get a book on information theory and crack it!
Thanks, Wyrd!
December 30th, 2021 at 9:53 am
You’re quite welcome! And thank you for an interesting discussion and some motivation to look into Shannon entropy. (Also, Merry Chillaxmas on this fifth of the 12 Days Of!
FWIW, I don’t see it as two different things. You said it yourself some time ago, things are different when the probabilities of different patterns (teas) differ than when they’re equal, yet the latter is just a special case of the former.
November 27th, 2021 at 10:48 am
A couple more questions:
The formula that shows log(5000 * 4900)… shouldn’t it be log(5000 * 4999)?
Also, I think it might help to be explicit about what a move is. Let’s say you take the first disc in the collection, put it in the back, and slide everything to the left one place on a hypothetical shelf. Does that mean all 5,000 discs are out of place or just one?
It strikes me the mathematics of one definition vs the other would be different in terms of possible micro-states. It’s not a detail necessary to understand the basic analogy, though.
So the idea of a sorted collection and it’s degree of being unsorted works well for giving a quick understanding of a macro-state and a micro-state. But I think to get into the math of it and to try and demonstrate this is a little tricky unless you define what a “move” is. If you want to restore the system to an ordered state, is a move a “swap” of two discs? Or is a move “taking a disc out and inserting it anywhere else”? Consider a three-disc set.
If the only moves permitted are “swaps,” then:
1 – 2 – 3 = 0 moves
2 – 1 – 3 ; 3 – 2 – 1 ; 1 – 3 – 2 = 1 move (did I miss any?)
But if you can take a disc and insert it anywhere, there is another single move micro-states. Then there would be all of the above, PLUS
2 – 3 – 1 ;
As you note, a challenge with a “sorting” example is the mathematics of determining how many moves are required for an arbitrary state is friggin’ complicated!
November 27th, 2021 at 2:25 pm
“The formula that shows log(5000 * 4900)… shouldn’t it be log(5000 * 4999)?”
Oops, yes! Sloppy fingers there. (At least I got the product right.) Fixed. Thank you!!
(You know the thing about proofreading? How it always take N+1 to find all the errors, where N is the actual number performed? The rule holds no matter how large N is.)
“Also, I think it might help to be explicit about what a move is.”
If I ever write Entropy 103, that would be a big part of the discussion, because it gets involved enough to need its own post. Here at the beginning, a “move” is taking one CD and putting it anywhere — an everyday interpretation of “moving a CD.”
When we start getting into the weeds, we do have to ask: is moving a CD one slot energetically different than moving it from one end of the collection to the other? Do we treat re-ordering the collection as a bubble sort would — moving items only one slot at a time? Do we implement in terms of swaps or moves? They’re similar, but what details are involved?
It starts getting into sorting, which is a major CS topic all on its own!
December 3rd, 2021 at 12:11 pm
I’ve been mucking around a bit with the basic Shannon entropy formula:
Take the five-bit case, which has 32 possible bit patterns. If all 32 of those have equal probability [P(x)=1/32] for all x, then the result is 5.0 (bits, because we’re using log2).
If I say one particular pattern has P(x)=1/2, and the rest all are P(x)=1/62 (giving us a total probability of 1.0), then the result is 3.477 (and change).
If I say one pattern has P(x)=9/10, and the rest are P(x)=1/10÷31 (so total probability is 1.0), then the result is 0.9644 (and change).
So when all patterns are equally likely, the result is the number of bits used, but as a given pattern becomes more likely than the others, the result becomes smaller and smaller.
Interesting!
December 10th, 2021 at 9:12 pm
See comments in next post for more about this…
December 9th, 2021 at 8:26 pm
This way of saying things may leave the wrong impression: “A macro-state is a property we can measure in a system. A macro-state is an overall property of the whole system, such as its temperature, pressure, or color.”
I think it is better to say, a macro-state is *all* the properties (or at least all the “relevant” ones) we can measure. For example, temperature 25 C AND pressure 101.3 kPa AND volume 1 m^3 AND 79% N2, 21% O2 AND no relative motion that we can observe of some regions of gas vs others in the cubic meter.
December 9th, 2021 at 10:33 pm
I get what you’re saying. My sense of it is that a full macro description of a system might involve multiple macro-states (such as temperature and pressure in a gas or fluid). The usual intent of a macro-state is that it is a single number describing the system. OTOH, a rigorous mathematical analysis of a system might indeed include multiple such macro-states plus initial and boundary conditions (such as composition and volume).
In a teaching analogy, the “gas” (when discussing thermodynamic gas systems) is abstract particles with only position and momentum. Whether they’re O2 or N2 or something else is a detail we ignore for simplicity. (A common metaphor for a gas system is a pool table where the “gas molecules” are just pool balls.) The CD collection abstracts things even further (into the info theory domain), and there is no real analogue for pressure and/or temperature; the macro-state is the elusive “how sorted” property. (In contrast, the size of the collection is an initial condition, not a macro-state.)
December 16th, 2021 at 6:38 pm
I believe Paul has this correct, Wyrd. Temperature and pressure are “macroscopic properties” of a macrostate. They are not the macrostate itself.
The macrostate of water (steam), for instance, must be identified by pressure and temperature (or some combination of two essential parameters, which is just something true about water that I cannot explain without a lot more thought). But without knowing at least two macroscopic properties for a given sample of steam (pressure and temp, pressure and enthalpy, temperature and enthalpy, pressure and quality, temperature and quality, temperature and entropy, pressure and entropy, etc.) then the macrostate isn’t fully defined. We can have two volumes of steam, for instance, with the same temperature, but vastly different pressures, and they would not be considered the same macrostate.
December 16th, 2021 at 6:47 pm
And just to clarify, if we know the pressure and temperature of a sample of steam (or water), we know as well the density, enthalpy, entropy, quality, internal energy, etc. We, in essence, know everything about the macrostate. It’s just because there cannot be two steam samples with the same pressure and temperature, but unique entropies, or unique enthalpies, or unique densities. This is just “how it is.”
December 16th, 2021 at 10:23 pm
I think we’re chewing on something of a phantasm here. I’ve never disagreed that a full description of a gas system involves more than just temperature or pressure. It’s not a topic I’ve discussed in detail at all. To the contrary, in such a system, as I indicated to Paul, I quite agree.
From my point of view, the link between temperature and pressure applies only to certain concrete systems. (An analysis of heating an iron bar wouldn’t require pressure, for example.) For purposes of a simplified abstraction, that’s extra detail that ends up being the same thing: a user-defined number (T,P) that indexes a macro-state.
FWIW, note that the macro-state here becomes a two-dimensional number, because the macro-states (50c, 14.8psi) and (14.8c, 50psi) are different states, so we can’t just take their sum or product. It doesn’t change anything, just makes our macro-state labels more involved. If we needed other “macroscopic properties,” then our macro-state vector would have more components.
December 21st, 2021 at 2:54 pm
[…] of a toy system used to illustrate the connection between “disorder” and entropy. (See Entropy 101 and Entropy 102.) I needed to calculate the minimum number of moves required to sort a disordered […]
January 6th, 2022 at 12:38 pm
[…] is about entropy and introduced the CD Library analogy I explored in detail recently (see: Entropy 101 and Entropy 102). It ranks #14 overall and #18 last […]
July 26th, 2024 at 7:15 am
[…] early post was about entropy. A more recent post discussed social entropy. The barrel of wine example illustrates why the lowest […]
July 4th, 2026 at 6:11 pm
[…] and still, I think, a good post. In the years since, I returned to the topic six times. See: Entropy 101 and Entropy 102 along with The Puzzle of Entropy, Entropy and Cosmology, and Entropy Isn’t […]