 Last week, when I posted about the Mathematical Universe Hypothesis (MUH), I noted that it has the same problem as the Block Universe Hypothesis (BUH): It needs to account for its apparent out-of-the-box complexity. In his book, Tegmark raises the issue, but doesn’t put it to bed.
Last week, when I posted about the Mathematical Universe Hypothesis (MUH), I noted that it has the same problem as the Block Universe Hypothesis (BUH): It needs to account for its apparent out-of-the-box complexity. In his book, Tegmark raises the issue, but doesn’t put it to bed.
He invokes the notion of Kolmogorov complexity, which, in a very general sense, is like comparing things based on the size of their ZIP file. It’s essentially a measure of the size of information content. Unfortunately, his examples raised my eyebrows a little.
Today I thought I’d explore why. (Turns out I’m glad I did.)
Honestly, I think Tegmark’s example is fine for those not familiar with mathematical complexity, but unfortunately it takes a swing at a detail and completely whiffs it. I doubt it matters — it’s way-down-in-the-weeds stuff — but it connects to something I’ve been laying the groundwork to talk about: whether real numbers are real.
His overall point is fine. I just think he winged something he should have thought about more. The bottom line is that two things that are supposed to be quite different are a bit closer than Tegmark imagined.
He starts with two images that look very much like these:

Which bitmap is made from random bits? [click for big]
Both images consist of 128×128 grids of black and white “pixels” (making 16,384 pixels in all). Can you tell which one is random?
Here’s what makes it worse: Any test we apply shows that both patterns have apparently random occurrences of black and white pixels. Measure them up, down, left, right; there is no regularity to find.
But one of them is genuinely random (within the ability of my computer to be random, which is a whole other topic), and the other, in which the bits do indeed occur randomly, comes from a specific sequence of bits.
One of them is the binary bits of the number: 
Can you tell which? (Yes, I have given you a big clue. (Rhymes with clue. Also ‘R’ stands for…))
§
The point of this is that, if we want to create a computer program that produces that specific random image (rather than a random image), the only way to do so is to store all 16,384 bits in the program and then, very simply, spit them out.
This means the size of the total program is large — at least 16,384 bits (2,048 bytes) — but the process involved, just spitting out stored data, is simple and short. The total size is not much more than the stored data size.
The other extreme is a program that has little data and lots of code. This obviously still results in a large program overall. (Most complex programs, such as Word or Excel, fall on this side of things. A program like Google Earth can be an exception. The database of Earth data is likely larger than the code. Most map programs would be exceptions.)
On the other hand, it’s possible for a program to be small but take lots of time to run. This doesn’t count against its size, which is all we’re talking about here.
The Kolmogorov complexity of something is a measure of the size of the smallest program that can create it.
One would think that highly complex objects require highly complex programs — long programs — to create them.
This turns out to not always be the case. The Mandelbrot, one of my favorite mathematical objects ever, is an awesomely complex (and stunningly beautiful) object that arises from a very simple program:
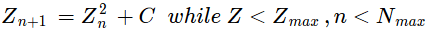
There’s a little more to it than that, but that’s the core. The basics of the amazing Mandelbrot are in that simple bit of code. From that we get images like the one at the top of this post.
§
Which brings us back to Tegmark and his images.
Here’s a more colorful version (same basic idea, but color-coding the decimal digits of the square root of two versus a random string of digits):

Color-coded decimal digit version. (e.g. “1”=red) [click for big]
He wants to make the point that the random image takes at least 16K-bits whereas he opines it takes only 100 bits to generate the square root of two. That’s the part that threw a flag on the play. 100 bits seems way too small; it’s just 12 bytes.
In fact, my gut sense was that the code size probably wasn’t terribly different than the data size of the random example. After looking into it… it’s close. It kinda depends on what we include.
In many program languages we can write something like:
sqrt(2)
Which is short (only 7 bytes) and does return the value we seek. In most languages it’s a library function we have to import, not a native capability. There are languages, though, ones that specialize in math, in which the function is native.
Spitting out the random bits doesn’t use these more advanced functions, and even in languages where they are native, they are sophisticated pieces of code. If we do include them, they’ll make our code rather large.
§
There’s a deeper problem here. Only in the most specialized languages does sqrt(2) give us what we need.
The problem is the bits — there are way too few of them. We need 16,384 of them — 2048 bytes worth. (Which is also our ceiling. If the square root code gets near that, it’s game over.)
Most systems use IEEE floating point, either single precision or double precision (often called float and double in programming languages). These give us a measly 24 or 53 bits, nowhere near enough. Not even close.
The biggest version, octuple precision, has 237 bits, but I don’t know any system that uses it, and it is still chump change for what we need. This is one of those places where we’re gonna have to roll our own.
§ §
So how to calculate the square root of two?
Let’s start by figuring out exactly what we need to end up with. We know we need 16K-bits. How many digits of the number are we even talking here?
We find that with: digits = bits × log10(2)
So: 16,384 × 0.30103 ˜ 4900+
We need to calculate
§
That’s some serious precision; none of the usual algorithms will work.
There is a definition of the value that might be usable. It’s the recursive fraction:

It’s simple enough; if we could code that, we might obtain a precise enough value for the number. What we get is a really large rational fraction that approximates the value. If we can get the approximation close enough, we’ll have what we need.
As it turns out, it’s pretty easy to code (albeit with a caveat):
function sqrt_tail (level): if (depth <= level): return (1,2) t = sqrt_tail(level+1) return ((2*t[0])+t[1], t[0]) function sqrt_of_two (depth): t = sqrt_tail(1) return (t[0]+t[1], t[0]) // Get value from 17000 levels deep! sqrt2 = sqrt_of_two(17000)
It’s not important to understand this code. Suffice to say it treats (p, q) pairs as rational numbers (p/q). It implements the recursive fraction above. The sqrt_tail function calls itself until it reaches the requested depth. Then it returns, starting with 1/2, and improving the accuracy each time it returns through a level.
The size of the fraction increases in each level. This creates a very large final number — hundreds of digits in both p and q. That’s not too hard to deal with. What’s more of an issue is how many levels of recursion are necessary. The code above calls for 17,000 levels, which I suspect is required to get the 4900+ digits of precision.
I say suspect, because Python barfs after 900+ levels, and at that point the accuracy is only 2287 bits of the 16,384 bits we need. The fraction has grown to 345 decimal digits by then (both numerator and denominator).
It’s possible to rewrite the code so it isn’t recursive, but then it will be larger. As you can see, it’s already above the 12 bytes Tegmark imagined, and we still have to turn the big fraction into bits.
§
We’ll do that with an integer division algorithm:
function divider (p, q, precision): if (q=0): error('Divide by zero!') quotient = [0] while (0 < p): if (q <= p): quotient[-1] += 1 p -= q else: if (precision < len(quotient)): break p *= 2 // we're working in base 2 quotient.append(0) return (quotient, p)
This function does a division to a specified level of precision. It returns a list of that many bits (the quotient) along with any remainder. Essentially we’re just subtracting q from p very much as in long division (except we don’t use multiples of q).
It’s not important to understand these algorithms. What’s important is that, combined, they are a lot more than 12 bytes.
I have a working version in Python. It’s got a few extras, like statements to display results and some timing instrumentation. The program is just under 900 bytes (7200 bits).
§
Which is certainly not 16K-bits, and Tegmark’s key point is that, while a truly random pattern pretty much requires just storing the pattern and spitting it out, apparently random patterns may have a much smaller Kolmogorov complexity — a much smaller program might create them.
That said, we are sanding off some corners here. Our code assumes the system can handle arbitrarily large integers. Python can because it has algorithms to do so. Including those makes our program larger.
We arguably should include them. As with the sqrt() function, handling arbitrarily large numbers is special — not something most systems supply natively.
To do this right we’d need to create a Turing Machine to generate the desired bits. Kolmogorov complexity really is in reference to the smallest TM that emits the desired pattern. That’s the only way to compare apples to apples.
§
The lesson here, I think, is that generating something that looks random still requires code size, even if it doesn’t require data size. That randomness demands code or data to generate it.
In contrast, the Mandelbrot images, which are rich with repeating patterns. Despite the greater resulting complexity, I think the regularity of the patterns reduces the code size.

A small piece of Mr. Mandel’s Beautiful Brot.
This ran long, so I have to leave the real number connections for another time. Very briefly, the MUH and BUH require extremely complex structures, which is contradictory to the view the Big Bang had zero, or extremely low, entropy. There seems a problem with where all the information came from.
As for why I’m glad I got into this, I’ve been putting off implementing a division algorithm for an arbitrary precision number class I’ve been working on. Division is the trickier of the standard four operations (+, -, ×, ÷), and I thought coding division for base-256 arbitrary precision was gonna be a challenge.
But this all made me realize (duh) I can just treat it as integer division and use the slow algorithm. Better than nothing!
Stay squared away, my friends!
∇












May 15th, 2020 at 2:09 pm
21 posts in 21 days. Time for a break! I’m gonna go curl up with VI Warshawski.
May 15th, 2020 at 6:49 pm
You’ve been on a blogging marathon!
I totally see your point for the numbers Tegmark presented. But it seems like his broader point would still hold. If we scaled the image up enough, eventually the economies of generating the numbers should be less than the numbers themselves.
That said, I don’t recall the context in which he presented that example. If it crucially depended on 16 kbits, then it does fall apart.
May 15th, 2020 at 8:24 pm
Yeah, I’m trying to knock back the backlog. I’m tired old draft posts and my piles of post ideas.
The broader point about generating vs storing a pattern absolutely holds. Instead of the 128×128 grid, it could be 1000×1000 for a million pixels. (If someone insisted on including all of Windows10 running Python, we just go for a trillion pixels. Whatever. We can eventually swamp the algorithm.)
It does mean serious recursion depth and huge numbers, but those are run-time concerns that don’t apply to Kolmogorov complexity. (It’s like a Turing Machine, time and memory are free and infinite.)
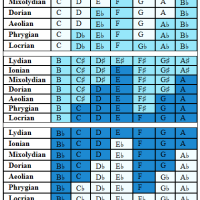
Tegmark’s point (this was later in the book where he’s defending his MUH), as I read it, was two-fold. Firstly, that a small algorithm can generate lots of data by tapping into the property of reality that allows complex structure to arise from simple rules. Secondly, that how complex something looks depends on the scale.
He compares the 128×128 bitmaps with 32×32 sections of them as well as 9×9 sections. IIRC, he thought the random 32×32 required 1,024 bits whereas the sqrt2 version only required the original 100 bits plus 14 more bits to specify the offset of the section. Conversely, both 9×9 sections are best described by their 81 bits.
Alarm bells went off for me here, since I hadn’t bought his 100-assertion. I think the 32×32 sections are very likely also best described by their 1,024 bits.
He’s not wrong about complexity, just could have chosen a better example. (Admittedly, only a geek like me would notice.) I think I know what he was going for. The actual information content of sqrt2 is, at a high level, very small. It’s just a number that’s the length of the diagonal of a square. Tegmark is focusing on how easy it is to specify that number at a high level without considering what it takes to actually produce it physically.
Unfortunately for Tegmark, as interesting as the discussion of complexity is, it does him no good in responding to the question about how his complex mathematical structures came to be. If he believes a Platonic abstraction can just be, it gets him out of it, but that’s a metaphysical leap of faith.
A secondary problem is that we know some information can only be generated algorithmically (the digits of sqrt2 are a good example, which may be another reason he chose it). So he’s faced with needing much of his MUH to be calculated.
By what? When? What generated this structure?
And I’ve realized it’s at odds with the general physics idea the universe started with low entropy which has been increasing. Our whole picture of the cosmos is of a progression in the process of generating increasing complexity.
Theorists get attached to their mathematical ideas due to their purity (the ideas, not the theorists). String theory and SUSY are two good examples. (So is another one,… what was it?… 😀 😀 )
May 16th, 2020 at 7:16 am
I actually have 46 drafts lying around. But I generally don’t spend a lot of time refining my posts, so most of the old drafts are just still-born efforts. Some, I started with a certain proposition, then realized after working through the details that I no longer bought it myself.
For me, the issue with the MUH is I see mathematics as a tool to model reality. Just because the tool can be used to model fictional concepts, doesn’t mean those concepts exist.
On string theory and SUSY, I’m with Hossenfelder here that the issue is their assumptions. I have some sympathy for physicists working on a TOE needing to make some assumptions or postulates. It’s just that each additional assumption is an opportunity to be wrong, and it sounds like those theories have a lot of them. (But I’m still not seeing how that applies to MWI, which I…assume is the other one, which actually removes an assumption.)
May 16th, 2020 at 9:20 am
I’ve had that happen where I start writing a post, get into it, and realize it’s more subtle or most complicated or, in a few cases, a lot less interesting to me than I thought. They sometimes live in my Drafts folder for a while until I’m sure I can’t do anything with them. Sometimes a little longer because it’s hard to throw away work. (Years is a “little longer,” isn’t it? 😮 )
I’m probably slightly more aligned with Smolin, Woit, and Baggott, than I am with Hossenfelder, although I generally agree with Hossenfelder, too. I think the issue goes deeper than starting assumptions (unless you’re saying the same thing). It’s, as Hossenfelder’s book title says, being “lost” in math. It’s thinking math is more than, as you said, a “tool to model reality.”
String theory and SUSY are ideas that haven’t panned out. (I guess one is required to add: so far.) The former, so far, is purely a mathematical playground. The latter, required by string theory and to unify the strong, weak, and EM, forces, has a closing experimental window of possibility. Many SUSY theories have already been eliminated.
That is one thing about those two… neither is just one clear theory. String “theory” really isn’t even a theory at all, just a set of mathematical ideas no one has made coherent yet. Of all of these, it’s the biggest fantasy. Purely a mathematical one. But SUSY is also a bunch of theories — moving goal posts as the window closes.
I’m not sure what more I can say about MWI. If you’re not skeptical, you’re not skeptical. If it’s a physical theory, it needs to account for how particles are physically duplicated. (How can E=mc2 continue to work?) If it’s not a physical theory (i.e. if it’s just reifying a mathematical description), then it’s mathematical fantasy.
May 16th, 2020 at 12:23 pm
Yeah, my drafts span the life of the blog. The oldest dates to November, 2013, the month I started. In addition to the cases I noted above, the topics in a lot of them were also handled by other later posts, or have just become obsolete over time. A few are backup copies of drafts that I decided to make radical changes to that were actually published. I need to clean it up at some point, although I really wouldn’t miss anything if I just deleted all of them.
I might need to go back and re-read Baggott on the MWI. I wasn’t nearly as familiar with it when I read his book. He has a new one coming out on quantum physics, which he’s tweeted will include fresh attacks on it.
May 19th, 2020 at 9:44 am
I’ve got a Draft that goes back to 2011 (but I plan to finally publish it soon — just need to re-watch the TNG episode it’s about). My recent “Spiders” post goes back to 2012. Nice to see them finally move out of the house!
I’ll have to look out for Baggott’s new book. Fresh attacks on quantum physics or specifically the MWI? (The more I think about MWI, the more I find people’s embracing it inexplicable.)
May 19th, 2020 at 3:03 pm
Baggott’s book is called Quantum Reality. It appears to be about quantum physics overall. He’s saying it’s no big deal. Historically when someone says that, I find them to be papering over the difficulties, but we’ll see.
I actually did go back and read what he wrote about MWI in Farewell to Reality. His assessment of it is tangled with discussion of string theory and other notions. It seems like he justifies disdain for some theories, then transfers that disdain over to others without specific justification. His conclusions appear more driven by simple outraged incredulity than I remembered.
May 19th, 2020 at 3:24 pm
No big deal? Yeah, color me skeptical, too. Reality is weird no matter how you slice it.
Without specifics I can’t respond to you responding to Baggott responding to physics… 🙂
May 19th, 2020 at 4:47 pm
Oh, sorry, I didn’t mean to imply I was looking for a response. It’s my overall impression of chapter 9 of his book, the one that covers MWI, eternal Inflation, and numerous multiverse concepts.
I’ll also add that, having read Brian Greene since my first reading of Baggott in 2013, I found that Greene exudes far less certitude than Baggott implies.
May 19th, 2020 at 4:59 pm
I think there’s no question Baggott crusades against something he perceives as problematic. I tend to agree more than disagree. String theory absorbed considerable time and energy with questionable returns. People can’t seem to let go of SUSY. I think we both worry it’s too much navel-gazing.
I haven’t read Greene in a long time, but I found him enjoyable when I did. (He’s the guy who convinced me String theory was such a winner.) To me he’s like Sean Carroll — someone I’ve known about and generally respected a long time but whom I think have gotten a bit too credulous for my enjoyment. I think it’s possible to be too open-minded.
May 19th, 2020 at 6:50 pm
I find Greene pretty measured in how he presents speculative theories. He’s clear that it’s a possibility, not empirically validated reality.
Carroll, I think, does wear his theoretical partisanship on his shoulder. Even he is careful to acknowledge when not everyone agrees with him. But the level of certitude he exudes is closer to the archetype Baggott criticizes.
May 19th, 2020 at 7:15 pm
I’d agree. I find Greene more wide-eyed than evangelical, like Carroll or Tegmark. I never felt Greene was trying to sell me something so much as trying to share his enthusiasm for it. That’s what made his string theory book so compelling.
Of course, Baggott, Hossenfelder, Woit, Smolin, and others, are singing their own evangelical song. It depends on which church one decides to attend. (And why.)
May 19th, 2020 at 10:23 pm
I just took a look at Baggott’s chapter nine. What he says about MWI seems accurate to me both in terms of explaining the view and the problems with it. I don’t see how it’s “tangled with discussion of string theory and other notions.” The MWI section stands alone.
From what I can tell he justifies his disdain in detail by discussing specific issues.
May 19th, 2020 at 4:48 pm
I wonder if, by no big deal, Baggott means wave-function collapse. It’s something I’ve been thinking about for a while — wave-function collapse is no big deal. Quantum physics is still weird and non-local, but that’s about the only huge difficulty one has to swallow — the non-locality.
But since it can’t be used to communicate, can’t be made use of at all, it’s censored away from sensible reality. Ultimately it means accepting reality has quantum correlations we can’t account for.
I’ve been working on a post for a while now about what I think is going on in w-f collapse. Nothing special, just decoherence. Weirdly, in a way, Everett was right, sort of, that the w-f doesn’t exactly go away. He was wrong (I think) in thinking it expands to include the measuring device, the observer, the rest of reality.
On the contrary, it’s transformed and damped out — swamped and lost in the larger system. What bothers physicists is lacking the math for a “collapse” — but there isn’t one, per se. There is just a fuzzy threshold where the information becomes indistinguishable.
Think about a single photon from the laser, through two slits, to some electron that absorbs it on the detector. Something capable of detecting a single photon will have energy itself necessary to amplify the photon being absorbed into an event with a tine and location. That photon begins life at the laser and ends it at the absorbing electron. The photon is gone.
Its information and energy are transformed into an excited electron which, because of the system configuration and energy, cascades to a large enough signal to record or announce at the macro level.
So we have a Schrödinger equation describing a system — the photon in flight. It provides a probability of finding the photon if we look in a given spot. This transforms into a different Schrödinger equation describing the excited electron. That electron is part of an atom, so the equation has to include it. It likewise has to include nearby atoms this atom interacts with.
As a result, the coherent information from the photon is simply absorbed, swamped, into the larger system. “Collapse” is simply a matter of scale — a quantum system exploding its information into the surrounding world.
May 19th, 2020 at 6:58 pm
I have to come clean that “no big deal” was my quick summation. Here’s what the first paragraph of the book description says. Note the part about “then all the mystery goes away.”
I find your description plausible, but to me the measurement problem remains. Why do we have a wave until we look at it, then a particle? And why is the particle in this location instead of that?
May 19th, 2020 at 7:31 pm
I would agree with Baggott (depending on exactly what he means). Quantum mechanics has a couple fundamental weirdnesses, non-locality, superposition, but after a while parts of it do make some degree of sense. I’ve gotten pretty comfortable with it, anyway. Maybe that’s what Baggott is presenting.
“Why do we have a wave until we look at it, then a particle?”
It’s always a wave, there’s no such thing as a “particle” — there are just localized manifestations of wave phenomenon. The photon is a wave packet and so is the electron that absorbs it. That electron wave packet changes state (to a higher energy one) due to absorbing the electron.
This higher state is amplified by a wave interaction between other atoms who’ve been somehow pumped with energy just below a threshold. The excited atom is able to provide bits of energy to several other atoms primed to change state. And so on like a fission reaction to some point enough atoms have changed state to do something macro.
But at no point is there ever a “particle” — just wave packets described by wave-functions.
(I think part of gaining a quantum mechanics intuition is forgetting any visual metaphor involving “particles” as little balls.)
“And why is the particle in this location instead of that?”
That’s a key question. (Under MWI it translates to “why this branch instead of that?”)
One possible answer: reality truly is random.
I don’t like that answer because it doesn’t really explain what’s going on with radioactive decay. How does a given uranium atom know it should decay? The overall rate of the group is astonishing precise given we have no clue how the atoms know.
It suggests to me a form of entanglement. If all the uranium atoms are partly entangled, if they can share some quantum states, then maybe there’s an evolving wave-function that selects a given atom as the most probable.
Likewise in the two-slit experiment, where the photon lands might depend on a partial entanglement among all parts of the experiment. Perhaps the massively complex wave-function — think chaotic lake surface in a good wind — does result in a given atom having the greatest probability of absorbing the photon.
November 11th, 2021 at 10:51 am
[…] It’s a companion to a post on my other blog. […]