 This is part four of a series commemorating BOOL, a computer language I started designing somewhere around 1990. After 30 years of sporadic progress, I finally gave up. There were so many contradictions and (for lack of a better word) “epicycles” in the design goals that it just wasn’t viable.
This is part four of a series commemorating BOOL, a computer language I started designing somewhere around 1990. After 30 years of sporadic progress, I finally gave up. There were so many contradictions and (for lack of a better word) “epicycles” in the design goals that it just wasn’t viable.
So, I’m mourning the passing of an idea that’s shared my headspace for three decades. Previously I’ve introduced BOOL and provided a tour of its basic aspects. Now I have to start talking about why it failed.
It has a lot to do with data, but that wasn’t the only issue.
One of BOOL’s primary design goals requires a 1:1 mapping between source code statements and compiled language objects. For instance, if the text contains an IF statement, this corresponds directly to an Actor object, @if, in the run-time (that Actor invokes the @if Action).
All computer languages map to run-time objects, but that mapping varies hugely among languages. In part to support automatic code analysis and proofing, functional code objects in BOOL are tree-shaped so they can be fully and predictably traversed.
Which all works great, except that the call mechanism became a hairy mess. I’ll get to that later (it comes under “wasn’t the only issue”).
§
The problem — what kept me spinning in circles for decades — was the data.
Reifying text into run-time code objects is fine, no problem. But when you do that with objects representing data, big problem. At least when one insists on not using a run-time stack. That was another design goal.
(The run-time stack is the source of a lot of hacker attacks. They’re all actually due to coding errors, but the combination of easy-to-make coding errors and the nature of a run-time stack often gives hackers a very useful entry point.)
Here’s the problem:
*int point-x *int point-y
Semantically, the above text fragment creates two BOOL Instance objects linked to the *int Model (in other words, two integer variables). One is named point-x, the other point-y (hyphens are allowed in names).
Under the hood, the text creates two meta-objects, which are BOOL-like objects that implement BOOL at the native level. Another design goal is that BOOL should be BOOL-like at all levels, so the underlying code that implements it, in whatever language that is, also follows BOOL design principles.
All BOOL objects contain, first, a reference to their handler. Invoking the object means invoking that handler. Meta-objects have references to the internal BOOL implementation and are invoked just like any BOOL object — by invoking the handler.
So, the two meta-objects the compiler creates first have a link to the native-code implementation for Instance objects. The meta-objects contain the *int Model instances with their link to the *int Model.
Think of it as an envelope within an envelope. The outer envelope is the meta-object. It’s addressed to the BOOL implementation handler for all Instance objects. The inner envelop is the Instance object, and it’s addressed to the *int Model. The contents of the inner envelop are keys to the integer data.
The point is these meta-instance objects cannot be modified at run-time, because they’re run-time code objects. Modifying code at run-time is a huge no-no, and BOOL makes no provision for it.
(Even if I went for it, they would only have one value, and there would be no way to have re-entrant functions. That kinda blows the whole thing sky high.)
§
I’m not kidding when I say I spent decades tinkering with this.
The caveat is that I’d only get into working on BOOL every couple or few years or so. I’d spend a month or whatever burning some fraction of my free time working on BOOL (I tend to skip around among projects).
Then I’d hit some point I really needed to think about, or some other point that really frustrated me, and I’d just hang it up until the mood caught me again (which, as I say, often took years).
So, it’s not like I put in 30 years of hard work on BOOL. I couldn’t really begin to estimate the actual total time. (It’s hard to calculate hobby time.) Still, I’m sure it amounts to a few years.
§ §
What I finally came up with a tripartite system:
- Read-only code objects (meta-Instances) define the data.
- Multiple intermediate “frame” objects enable re-entry.
- The Model manages the actual data bits.
The design works fine, but it’s more complicated than I wanted.
The problem was that Models need some kind of reference counting to know when they can discard bits and free the memory space.
That’s enough of a PITA that I considered making it the programmer’s responsibility to delete data, but [A] I like garbage-collecting languages and [B] there are too many transitory data objects the programmer knows nothing about. They create a massive memory leak.
[In an expression like (3+(4*5)) the computer, of course, has to physically generate the (4*5) part. This creates a temporary data object, 20, that has to be the same type as the others. In languages where objects are non-trivial, this requires cleaning up those non-trivial temporary objects.]
So BOOL needs GC, which requires a careful analysis of how Models handle data. It also requires adding the mechanism for clients to register references. I just didn’t feel like getting that deeply into it.
(I have a working version of BOOL that simply ignores the problem. Once bits are allocated to a datum, that memory is gone for the rest of the run. Memory gets used up quickly, but it works for short runs.)
§
I do like the design. The Instance object defines what the data is expected to be — usually is except in the case of anonymous data (*one, *list, *any). Alternately, the Instance might specify a base object but end with a derived object.
The Instance object also has the optional default list with the datum’s default value(s). (That default value is assigned at run-time when the execution thread encounters the Instance object. It can be reassigned by sending a reset: message to the object.)
The Instance object has a unique index into the Call Frame that is generated for every entry into a procedure. A Call Frame is analogous to the call frame on a run-time stack but is a read-only internally mediated object that can’t be tampered with.
The Instance object index addresses an Intermediate object in the Call Frame. This frame object identifies the data’s actual run-time Model. It also has a data-key for the actual data bits allocated by the Model.
The only access to the actual data bits is through that key. All Model operations on data require that key for access.
By the way, this is all system-level stuff mediated by the run-time engine and not accessible in any way to user code (malicious, accidental, or otherwise). All the user ever knows is:
*int point-x *int point-y
That text creates two data Instances, both of the *int (integer) Model. All that can ever happen to them is getting messages which evaluate to requests to their Model to do something with their data bits.
For instance, this code sets both objects to forty-two:
set: point-x 42 set: point-y 42
As an aside, regarding those “42” text literals. The first time BOOL sees a particular literal (be it number, string, date, etc), it creates an instance object of the appropriate Model (in this case *int). In the code, as described below, all references to literal values are references to global constant data objects.
§ §
I’ve talked before about messaging sending. I’d like to dig into that a little deeper now. The details here involve fundamental aspect of BOOL’s behavior.

BOOL-level version of how a set: statement compiles.
The set: text compiles to a Message meta-object (named “set”). As per all meta-objects, this first links to a run-time handler for Message object behavior. Unlike Actor objects linking to Actions, or instance objects linking to Models, Message objects just have a name: their message.
So, the set: Message object is named “set” — obviously names are not required to be unique as both Messages objects in the code fragment above would have the same name.
Message objects have two links: target and parameter. The target object will receive the message.
The targets in the code above are the two *int objects, point-x and point-y. The parameter object (which can be null) is data for the target. In the code fragment, the parameters are references to the “42” global object.
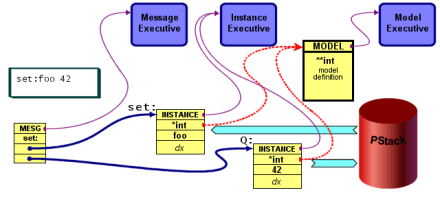
Meta-level version of how a set: statement compiles.
At run-time, the Message object (activated by receiving its own message) first sends a “query” message (Q:) to the parameter object (if not null). The parameter can be a sub-tree of objects requiring evaluation to produce a result object (in other words, an expression or function of some kind).
The Q: message makes the parameter object(s) evaluate, the end result of which is pushing a single value object on the parameter stack.
Then the Message object sends its name to the target object (which may also need to evaluate to some final object). The target object invokes its Model to find a handler for the message. It presumes it can find a value object on the parameter stack (if it needs one).
§
The steps for just the first line above are:
- set: Message receives X: (execute) message from RTE.
- set: Message sends Q: to the “42” object.
- “42” object invokes *int Model with self and Q: message.
- *int Model pushes a reference to “42” object onto p-stack.
- set: Message sends set: to *int object (point-x).
- *int object invokes *int Model with self and set: message.
- *int Model finds @set Model Action; invokes with *int object.
- @set Action requires a parameter; pops “42” reference off p-stack.
- @set Action sets value of *int object (point-x) to “42”.
- @set Action pushes reference to *int object onto p-stack.
- set: Message got an X: message, so it discards the p-stack reference.
If the set: (or any) Message receives a Q: (query) or other value-inducing message (rather than the X: message), it leaves the p-stack alone — someone else expects that value.
§ §
This ran longer than intended, so I’ll end abruptly and finish tomorrow.
Stay boolean, my friends!
∇













June 14th, 2024 at 1:04 pm
[…] Last time I talked about how BOOL handles data and why that was such an issue. This time I’ll ramble on about some of the other snarls that ultimately made things more complicated than I wanted. Simplicity and elegance were key design goals. I intended the run-time environment, especially, to be utterly straightforward. […]